Organising the Archive
-
@biell I can find a few things on archive.org but I found searching with it was extra tedious so I'm planning to find the rest if I can through it since that wasn't time sensitive.
If you're sure, thank you so much for the effort you put in <3
That's really helpful. I'll cast an eye through it, might learn a thing or two as I do :)
-
@lia The Perl script can be found here:
https://drive.google.com/file/d/1UoQaB3_wzojQOilSgkt-TNamNYDRqwLU/view?usp=sharing
Basically, I assume you have a folder somewhere and it contains folders, each of which look like the zip file you sent me. If so, you could litterally just run
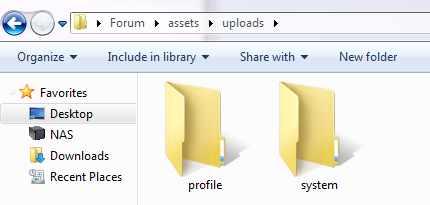
forum_archive *in that location and it would read through all the sub-folders, then neatly pack everything under aassetsand atopicfolder, with you just having to move those two directory structures into your webserver's DocRoot.I don't think I used any Perl modules you wouldn't find standard.
Please let me know if you have any questions.
-
@biell Thank you :)
I'll hopefully give it a whirl this weekend since it's raining here anyway so plenty of indoor time to work with.Thank you for making this :)
-
@biell Finally found time to give it a whirl. Not sure if it's Windows or what I'm doing but I can't get it to work properly. Probably something I'm doing no doubt >.>
Using StrawberryPerl on a Windows10 Laptop.
Renamed the file to forum_archive.pl as windows couldn't figure out what to do with it in cmd.
Script exists in a directory (Forum) and inside with the script is a folder called RAW where I'm dumping all the cache scrapings.
Here is a Tree of that if it's easier to follow (note 2 and 22 were separated for testing later).
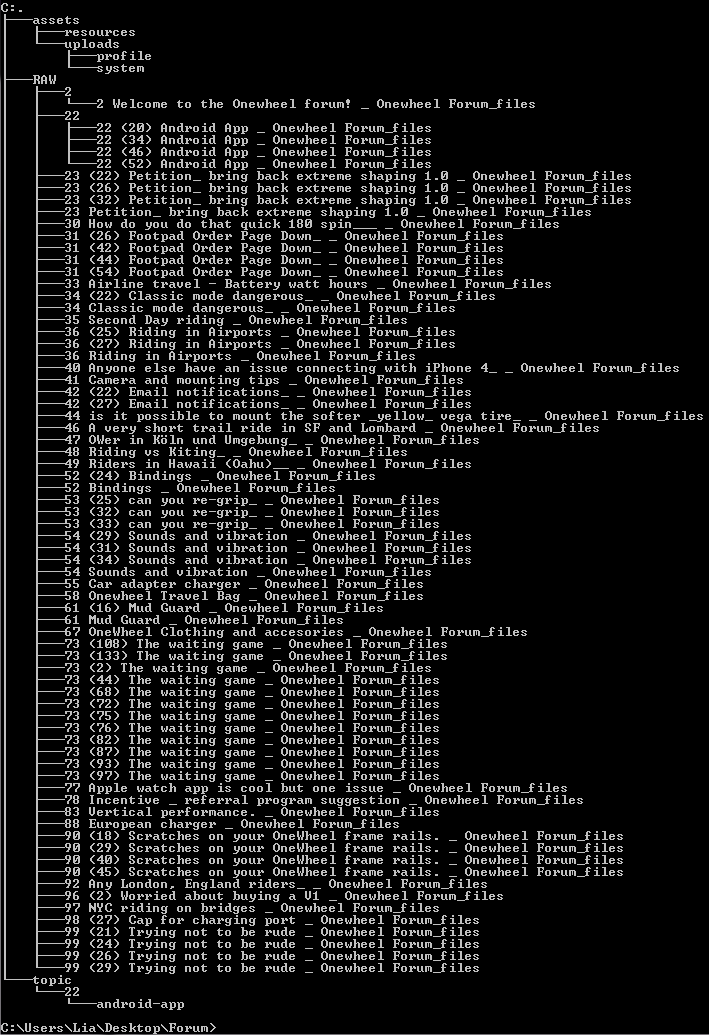
If I run "forum_archive.pl *" it complains it wants a specific directory.

"forum_archive.pl RAW" runs it but then states an illegal division by zero on line 451 occurred when trying to give the "missing" field.

If I place the topics in their own directory rather than all in the same one it runs and completes but doesn't move any of the images to the resources directory.

If a topic only has a single entry to run it gives the division by zero error again. I assume this might be what is causing the "forum_archive.pl RAW" command to fail.

I've zipped up exactly what I have currently with a selection of files in RAW. I've left topic 2 and 22 as separated so you can see what worked and what didn't.
Forum.zip -
@lia I will look into this. I see a couple things. Firstly, I made a couple mistakes because I only had a single topic to test against (oops). Second, I was expecting everything to be organized like your "2" and "22" directories, I may have to do some finagling to handle multiple topics in the same directory.
Also, I see that topic "2" is causing an issue, so I will work through that now that I have more data.
Please just give me a few days to iron this out. Sorry about that. I may need some consistency between either the organization like topic 22 or topic 23.
-
@biell said in Organising the Archive:
Firstly, I made a couple mistakes
What??? Mistakes in software??? This can not be!!! /s ... I'm a retired software engineer :D
-
@biell Thank you :) no rush on it at all, been caught up in a few things so haven’t been able to focus on much.
My fault for not providing more test data, a single example was a bit dim of me to provide.
-
i had a post about my flightfin switch install. is that saved in the archive somewhere by any chance?
-
@swinefeaster One of the ones I specifically looked for when I started the project. I have it.
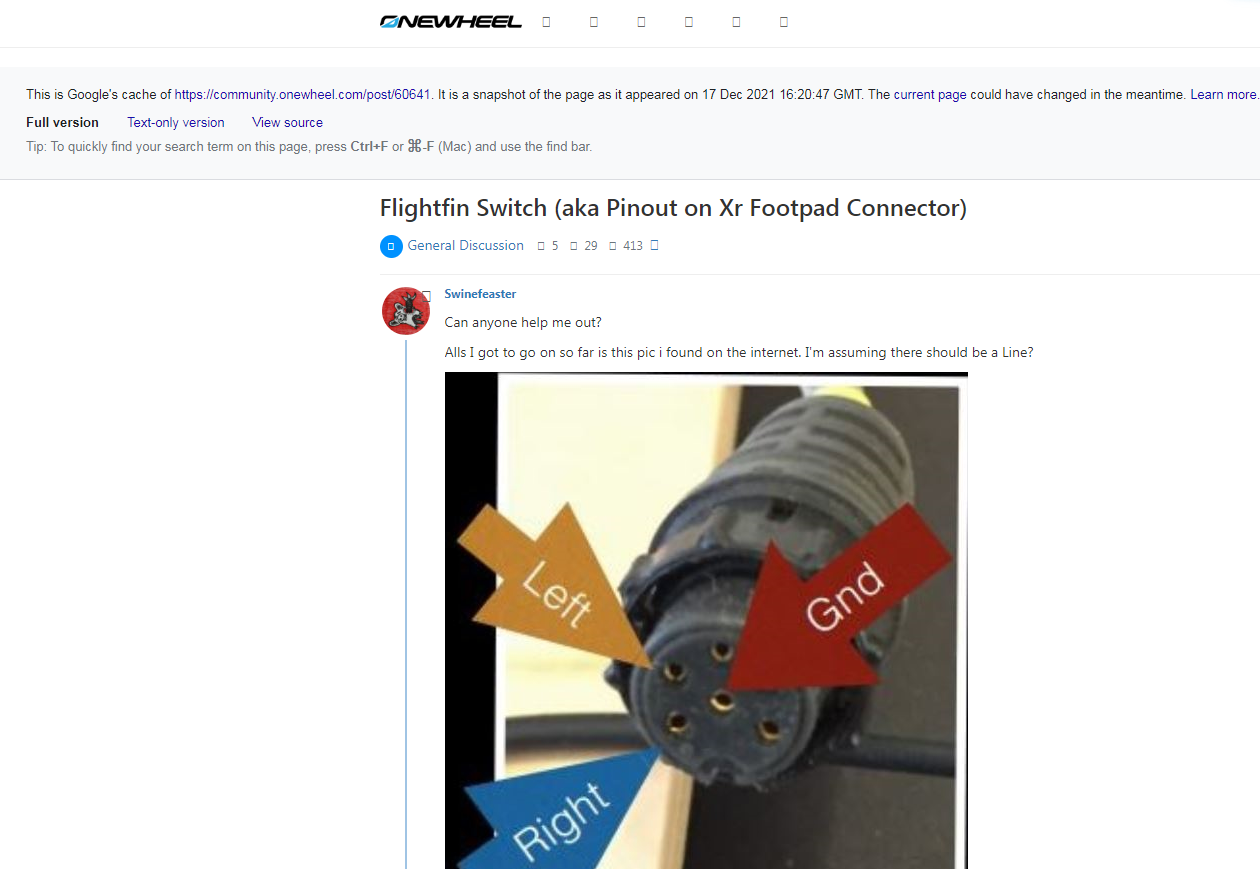
Shall be up soon, I might manually do this one since it's only 29 posts long.
-
@swinefeaster Patched it up and uploaded it :)

Linky -
@lia you're awesome thanks!
-
@lia Just a quick update on this. I didn't get a chance to start digging in until yesterday. I have mostly fixed everything. Your current directory structure with mixed folders/not-folders is working, and all the uploads are getting sorted properly.
When troubleshooting the div-by-zero error, I found that it was happening because something was moved to the bottom of the HTML on some pages (and so my
$COUNTvariable wasn't getting initialized. Well, it turns out some pages (e.g. topic 99) have a COMPLETELY different format with a<div class="post-bar">. These pages have a total lack of proper CSS styling (avatars are messed up, the timeline doesn't show, ...).Some topics have all their pages like this, but most don't. For example, topic 54 only has one file in this weird format:
54 (34) Sounds and vibration _ Onewheel Forum.html.So, I am going through all that now to get these pages to render as close to the rest of the archive as possible. I think I have everything done except to copy the information from the bottom of the page back up to the top (posters, posts, and views).
-
$ ./forum_archive.pl RAW topic/2/welcome-to-the-onewheel-forum, Total: 3, Coverage: 100%, Missing: None topic/20/france-onewheel-riders, Total: 2276, Coverage: 80%, Missing: 0-47 83-120 160-169 249-253 274-281 302-339 384-397 523-527 566-581 687-704 880-892 940-943 1040-1041 1062-1072 1110-1111 1244-1253 1287-1312 1333-1339 1455-1459 1487-1492 1834-1842 1902-1996 2017-2025 2128-2139 2176-2193 2228-2238 2272-2275 topic/22/android-app, Total: 58, Coverage: 82%, Missing: 0-9 topic/23/petition-bring-back-extreme-shaping-1-0, Total: 26, Coverage: 100%, Missing: None topic/30/how-do-you-do-that-quick-180-spin, Total: 20, Coverage: 100%, Missing: None topic/31/footpad-order-page-down, Total: 69, Coverage: 69%, Missing: 0-15 64-68 topic/33/airline-travel-battery-watt-hours, Total: 8, Coverage: 100%, Missing: None topic/34/classic-mode-dangerous, Total: 23, Coverage: 100%, Missing: None topic/35/second-day-riding, Total: 2, Coverage: 100%, Missing: None topic/36/riding-in-airports, Total: 28, Coverage: 100%, Missing: None topic/40/anyone-else-have-an-issue-connecting-with-iphone-4, Total: 3, Coverage: 100%, Missing: None topic/41/camera-and-mounting-tips, Total: 22, Coverage: 90%, Missing: 20-21 topic/42/email-notifications, Total: 35, Coverage: 51%, Missing: 0-16 topic/44/is-it-possible-to-mount-the-softer-yellow-vega-tire, Total: 10, Coverage: 100%, Missing: None topic/46/a-very-short-trail-ride-in-sf-and-lombard, Total: 19, Coverage: 100%, Missing: None topic/47/ower-in-k%C3%B6ln-und-umgebung, Total: 3, Coverage: 100%, Missing: None topic/48/riding-vs-kiting, Total: 2, Coverage: 100%, Missing: None topic/49/riders-in-hawaii-oahu, Total: 5, Coverage: 100%, Missing: None topic/52/bindings, Total: 24, Coverage: 100%, Missing: None topic/53/can-you-re-grip, Total: 61, Coverage: 45%, Missing: 0-14 43-60 topic/54/sounds-and-vibration, Total: 34, Coverage: 100%, Missing: None topic/55/car-adapter-charger, Total: 17, Coverage: 100%, Missing: None topic/58/onewheel-travel-bag, Total: 10, Coverage: 100%, Missing: None topic/61/mud-guard, Total: 31, Coverage: 83%, Missing: 26-30 topic/67/onewheel-clothing-and-accesories, Total: 13, Coverage: 100%, Missing: None topic/73/the-waiting-game, Total: 133, Coverage: 82%, Missing: 20-33 54-57 118-122 topic/77/apple-watch-app-is-cool-but-one-issue, Total: 17, Coverage: 100%, Missing: None topic/78/incentive-referral-program-suggestion, Total: 11, Coverage: 100%, Missing: None topic/83/vertical-performance, Total: 4, Coverage: 100%, Missing: None topic/88/european-charger, Total: 3, Coverage: 100%, Missing: None topic/90/scratches-on-your-onewheel-frame-rails, Total: 49, Coverage: 83%, Missing: 0-7 topic/92/any-london-england-riders, Total: 8, Coverage: 100%, Missing: None topic/96/worried-about-buying-a-v1, Total: 10, Coverage: 100%, Missing: None topic/97/nyc-riding-on-bridges, Total: 16, Coverage: 100%, Missing: None topic/98/cap-for-charging-port, Total: 29, Coverage: 41%, Missing: 0-16 topic/99/trying-not-to-be-rude, Total: 31, Coverage: 64%, Missing: 0-10 $My run (I included topic 20): https://drive.google.com/file/d/1jlOmlSBb-Hi2Dimhn5URw6tfA8Uro-U1/view
The updated script: https://drive.google.com/file/d/1FFmb1LVADMPUvIMumuJdX50xRmqIq7iM/view
Note that the script is a little hacked up now to deal with copying the header up to the top when it is at the bottom.
-
@biell Thank you so much :) Taken a peak at your run and it looks good, will give that a whirl myself with the bulk of it and see how it gets on. Might need to discard some posts as you point out a handful are a bit busted so I can manually do them later if needed :)
Really love the output for the stitching. Will give me a reference of what I need to look at and what's good to set in stone.
-
Code works. Thanks @biell

It's churned through all the topics. Total is just over 1000 currently which is pretty decent.
Made a really simple .bat to run the perl script and spit out the console into a txt so I have the page stats to hand for later refining :3However I am now manually adding the links to those pages onto the homepage.
Wish me luck...

Updating this as I go
Topics 0-9600 links have been added
Only what exists of course. (1180/1180) -
@lia Great news, I have been worried about this for a bit. If you run into any issues, don't hesitate to reach out.
-
@biell I'm steamrolling adding the links to the homepage now they're practically all there :) Thank you for getting me to the home stretch! Hope you enjoy seeing your contribution in action as much as I am with all the pages pretty much being restored :D
Sorry the delay worried you. The past month has been brutal D:
I think I somehow broke 2 bits but not sure what, maybe me editing some bits busted the formatting.
Timestamps aren't generating and some avatars are being broken :( The script mentions line 344 has a regex error or something.The slightly modified script is below. I altered the value for "logo_ht" from 80 to 60 and changed the image on my end to a newer version.
#!/usr/bin/perl =head1 NAME forum-archive - Put a google chached community.onewheel.com thread back together =cut use IO::Handle; use HTTP::Request; use LWP::UserAgent; use File::Copy; use File::Path; use File::Find; use Pod::Usage; use POSIX; my($HEADER, @POSTS, $FOOTER, $COUNT, $WEIRD); my(%META)=( 'base' => 'https://archive.owforum.co.uk/', 'logo' => 'http://archive.owforum.co.uk/Images/OWForumArchive.png', 'logo_ht' => '60', 'profiles' => '../../../assets/uploads/profile', 'resources' => '../../../assets/resources', 'system' => '../../../assets/uploads/system', ); my(%RESOURCES)=( 'fonts' => 'https://cdnjs.cloudflare.com/ajax/libs/font-awesome/5.15.4/css/all.min.css', 'style' => 'https://owforum.co.uk/assets/client-darkly.css', 'icon' => 'https://owforum.co.uk/assets/uploads/system/favicon.ico', 'broken' => 'https://icon-icons.com/downloadimage.php?id=5390&root=39/PNG/128/&file=brokenfile_5952.png', ); my(%TOPICS)=(); my(%SEARCH_PATH)=(); =head1 SYNOPSIS forum_archive <directory1> [directory2] [directory3] [...] =head1 DESCRIPTION This script takes a set of files downloaded from the google page cache for the community.onewheel.com NodeBB forum and tries to put it back together. =head2 Content Management A small number of resources are available from the internet. B<forum_archive> will download these assets, if needed, for inclusion to the archive file structure. If assets have been downloaded recently (within the last day) then new downloads are not attempted. This should keep B<forum_archive> from slamming remote resources during testing phases. =cut sub wget { my($src, $asset, $dst)=@_; my($file)=IO::Handle->new; my($req)=HTTP::Request->new( 'GET' => $src ); my($get)=LWP::UserAgent->new; my($response); $asset=~s|^[/.]+||; if(!-s "$asset/$dst" || -M "$asset/$dst" > 1 ) { $response=$get->request($req); if($response->is_success) { File::Path::make_path($asset, { 'chmod' => 0755 }); open($file, '>', "$asset/$dst"); print $file $response->decoded_content; close($file); } } } =pod B<forum_archive> will dynamically create the C<assets> and C<topic> directory structures as needed to store content found within the post. In an effort to increase efficiency for commonly used content, such as avatars, actual copying of these files will not occur each time such content is seen, after its initial copy. =cut sub location { my($file)=@_; my($try); if(-r $file) { return($file); } else { foreach my $dir (keys(%SEARCH_PATH)) { $try=join('/', $dir, $file); return($try) if(-r $try); } } &wget($RESOURCES{'broken'}, $META{'resources'}, 'broken-file.png'); return(join('/', $META{'resources'}, 'broken-file.png')); } sub copy { my($src, $asset, $dst)=@_; $asset=~s|^[/.]+||; if(!-s "$asset/$dst" || -M "$asset/$dst" > 1 ) { File::Path::make_path($asset, { 'chmod' => 0755 }); File::Copy::copy(&location($src), "$asset/$dst"); } } =pod Avatar image are stored in a central location, shared by the entire archive. This lowers the space requirements of the archive and increases page load times and browser cache efficiency. =cut sub avatar { my($img)=@_; my($dst)=$img; $dst=~s|^.*/||; ©($img, $META{'profiles'}, $dst); return(join('/', $META{'profiles'}, $dst)); } =pod Uploaded images which are stored in the archive may be named slightly differently on the archive than on the original. NodeBB has gone through a couple iterations about how to handle this conflict, and B<forum_archive> tries to handle this by using the more unique C<ALT> tag element parameter name. When that doesn't work, the original name is kept. Images are also grouped by post, to avoid naming conflicts between different posts. Additionally, if an image is referenced in a post, but is not contained in the archive, a standard broken file image is substituded. =cut sub upload { my($src, $alt)=@_; if($alt=~m/\.\w+$/) { ©($src, $META{'path'}, $alt); return(sprintf('<img src="%s" alt="%s"', $alt, $alt)); } else { my($new)=$src; $new=~s|^.*/||; ©($src, $META{'path'}, $new); return(sprintf('<img src="%s" alt="%s"', $new, $alt)); } } =head2 Archive Display One major change in the archive from the original is the banner. The original banner is replaced by one tailored to the archive, to set it apart from the original forum and make it clear it is a wholly different entity. =cut sub banner { my($start, $img, $end)=@_; return($start.qq{ <div class="container"> <div class="navbar-header"> <a href="http://archive.owforum.co.uk"> <img alt="The Archive homepage" src="$META{'logo'}" height="$META{'logo_ht'}"> </a> </div> <div class="navbar-header pull-right"> <p class="text-right" style="padding-top: 10px"> This page is an archived copy of the old Onewheel Forum. </p> </div> </div> }.$end); } =pod One of the differences which makes the archive different is, unfortunately, that some posts are missing. When this occurs, B<forum_archive> inserts a break in the timeline with a note about the message IDs which are absent. =cut sub missing_post { my($id)=@_; return(qq{ <li component="topic/necro-post" class=" necro-post timeline-event" data-index="$id"> <small class="timeline-text">Post(s) $id missing from the archive</small> </li> }); } =pod An interactive, HTML5 based NodeBB forum requires a lot of javascript to work. Since the archive is a static copy of that data, all of the javascript is removed, and the archive works nearly identically on all platforms. =cut sub global { s|https?://community.onewheel.com/|$META{'base'}|sg; s|<noscript>.*?</noscript>||sg; s|<script>.*?</script>||sg; s|<script .*?></script>||sg; s|\s+<div component="topic/reply/container" .*?</div>||s; s|\s+<a component="topic/reply/guest" .*?</a>||m; s|class="posts"|class="posts timeline"|mg; s|\n\n<hr>\n||sg; if(m|<span component="topic/post-count".*?>(\d+)</span>|m) { $COUNT=$1; } } =pod B<forum_archive> assumes that all the headers from all the source files are identical, and uses the first one it finds. With that content, the new banner is inserted, interactive metadata and buttons are removed, and the new style is setup. B<forum_archive> also collects important information like the page path and total message count. =cut sub header { local($_)=@_; #Cleanup to a reasonable starting header only s/(<ul component="topic" class="posts timeline" .*?>\s+).*$/$1/s; s/(<body .*?>).*$/$1/m; #Grab some important info if(m|<link rel="canonical" href="($META{'base'}(.*?))">|) { $META{'url'}=$1; $META{'path'}=$2; } #reset links #strip out unneeded content s|(<meta property="og:url" content=".*?)/\d+\?.*?">|$1">|mg; s|\s+<meta name="msapplication-\w+" .*?>||sg; s|\s+<link rel="icon" sizes=.*?>||sg; s|\s+<link rel="prefetch" .*?>||sg; s|\s+<link rel="prefetch stylesheet" .*?>||sg; s|\s+<link rel="manifest" .*?>||sg; s|\s+<link rel="search" .*?>||sg; s|\s+<link rel="apple-touch-icon" .*?>||sg; s|\s+<link rel="alternate" .*?>||sg; s|\s+<link rel="next" .*?>||sg; s|\s+<link rel="prev" .*?>||sg; &wget($RESOURCES{'icon'}, $META{'resources'}, 'favicon.ico'); s|(<link rel="icon" type="image/x-icon" href=").*?">|$1$META{'resources'}/favicon.ico">|mg; &wget($RESOURCES{'style'}, $META{'resources'}, 'client-darkly.css'); s|<link rel="stylesheet" .*?>|<link rel="stylesheet" href="$META{'resources'}/client-darkly.css">\n\t<link rel="stylesheet" href="$RESOURCES{'fonts'}">|s; if(m|forum-logo" src="(.*?/site-logo.png)"|m) { ©($1, $META{'system'}, 'site-logo.png'); s|forum-logo" src=".*?"|forum-logo" src="$META{'system'}/site-logo.png"|mg; } s|(<h1 component="post/header" .*?)>|$1 style="padding-top: 50px;">|m; s|\s+<section class="menu-section".*?</section>||s; #Insert new banner s|(<nav class="navbar navbar-default navbar-fixed-top header".*?>).*?<img alt="Onewheel Home Page" class=" forum-logo" src="(.*?)">.*?</nav>|&banner($1, $2, '</nav>')|se; #Remove unnecessary buttons s|\s+<a class="hidden-xs" target="_blank".*rss.*</a>||mg; s|\s+<div title="Sort by" .*?</div>||s; s|<li>[^RL]+<span>Register</span>.*?</li>||gs; s|<li>[^RL]+<span>Login</span>.*?</li>||gs; s|<a component="topic/reply/guest" .*?</a>\s*||s; s|<ol class="breadcrumb">.*?</ol>||s; s|<span class="hidden-xs">Loading More Posts</span> <i .*?</i>||mg; s|class="slideout-panel" style=".*?"|class="slideout-panel"|m; return($_); } =pod A lot of cleanup occurs within each forum post. Firstly, and with the javascript removed, all times are calculated and coded directly in UTC. Interactive buttons are removed, and links to content (such as user pages) not contained in the archive are also removed. Other interactive content (e.g. online status) is removed, too. Media, such as avatars and uploaded content is collected and placed properly into the new archive filesystem structures. =cut sub post { local($_)=@_; my($time); if(m/data-timestamp="(\d+)"/s) { $time=POSIX::strftime("%e %B %Y, %H:%M UTC", gmtime($1/1000)); s|(><span class="timeago") title="(.+?)">|$1 title="$time" datetime="$2">$time|sg; } s|<span class="replies-last .*</span>||mg; s|<a component="post/parent" .*?>(.*?)</a>|$1|mg; s|<i component="user/status" .*?></i>||mg; s|<a href=".*?/user/.*?">(.*?)</a>|<span class="btn-link">$1</span>|sg; s|<a class="plugin-mentions-user .*?>(.*?)</a>|<span class="btn-link">$1</span>|mg; s|<a href="[^"]+/user/.*?">\s+(<span class="avatar.*?>)\s+</a>|$1|sg; s|(?<= component="user/picture" src=")([^"]+)|&avatar($1)|meg; s|(?<= component="avatar/picture" src=")([^"]+)|&avatar($1)|meg; s|<img src="(.*?)" alt="(.*?)"(?= \s*class="\s*img-responsive)|&upload($1, $2)|meg; s|<a (component="post/reply-count".*? href=").*?/(\d+)[?#].*?(".*?)>|<a $1#$2$3>|mg; s|\s+<i component="post/edit-indicator".*?</i>||mg; s|\s+<i class="fa fa-fw fa-chevron-right".*?</i>||mg; s|\s+<i class="fa fa-fw fa-chevron-down hidden".*?</i>||mg; s|\s+<i class="fa fa-fw fa-spin fa-spinner hidden".*?</i>||mg; s|\s+<small class="pull-right">\s+<span class="bookmarked">.*?</span>\s+</small>||sg; s|(?<= class="avatar" src=")([^"]+)|&avatar($1)|meg; s|(?<= component="user/picture" data-uid="\d{1,5}" src=")([^"]+)|&avatar($1)|meg; s|(<img component="user/picture")|$1 class="avatar avatar-sm2x avatar-rounded"|mg; s|(data-uid="\d+") class="user-icon"|$1 class="avatar avatar-sm2x avatar-rounded"|mg; s|(title="\w+") class="user-icon"|$1 class="avatar avatar-xs avatar-rounded"|mg; s|id="[^"]*google-cache-hdr"||sg; s|This is Google's cache of||sg; return($_); } =pod Similarly to the header, the HTML after all the posts is based on the first file seen and removes some of the content better suited to an interactive stite than a static, archive site. =cut sub footer { local($_)=@_; s|<div class="progress-bar"></div>||s; s|<div class="spinner" role="spinner"><div .*?</div></div>||s; s|<div id="nprogress">.*?</div></div></div>||s; return($_); } =head2 Data Import Process Each downloaded F<.html> file from the forum is read and separated into 3 sections, a header, a list of posts, and a footer. The first file's header will be processed and used as the archive files header, same with the footer. Each post is pulled into an array. If a post occurs in multiple downloaded cache files, then the last one read is kept. Each one is processed and prepared for the final archive topic. =cut sub ingest { my($source)=@_; my($html)=IO::Handle->new; my($move, $category_url, $category); local($/)="\n\t\t\t\t</li>\n\t\t\t"; open($html, '<', $source); while(<$html>) { &global; if(m/^<!DOCTYPE html>/) { if(m/class="nprogress-busy"/) { $WEIRD=0; } else { $WEIRD=1; } if(!$HEADER || !$WEIRD) { $HEADER=&header($_); } s/^.*<ul component="topic" class="posts timeline" .*?>\s+\n//s; } if(m|</html>$|) { if(!$FOOTER || !$WEIRD) { $FOOTER=&footer($_); if($FOOTER=~s|(<div class="post-bar">.*\n<hr>\n\t\t</div>)||s) { $move=$1; ($category)=($HEADER=~m|<meta property="article:section" content="(.*?)">|m); ($category_url)=($HEADER=~m|<link rel="up" href="(.*?)">|m); $category=~s/&/&/g; $HEADER=~s|</h1>\n|</h1>\n$move|s; $HEADER=~s|<div class="tags pull-left">.*<div class="topic-main-buttons pull-right">|<div class="topic-main-buttons pull-left"><a href="$category_url">$category</a>|s; $HEADER=~s|class="stats hidden-xs"|class="stats text-muted"|mg; $HEADER=~s|(<span component="topic/post-count" class="human-readable-number" title="\d+">\d+</span>)<br>\s+<small>Posts</small>|<i class="fa fa-fw fa-pencil" title="Posts"></i>$1|s; $HEADER=~s|(<span class="human-readable-number" title="\d+">\d+</span>)<br>\s+<small>Views</small>|<i class="fa fa-fw fa-eye" title="Views"></i>$1|s; } } last; } if(m/data-index="(\d+)"/) { $POSTS[$1]=&post($_); } } close($html); } =head2 Execution The script expects a directory structure of HTML files which have valid links to media files. Other than that, it is pretty agnostic about the structure of the directory. It will read the header to find out what the name of the document should be, create it, and write to it. In addition to processing archived posts, a special post is inserted for anything missing. B<forum_archive> will also produce a report on F<STDOUT> with information on missing posts. =cut sub process { my($html)=IO::Handle->new; my($posts, $total)=(0, 0); my(@missing)=(); $HEADER=""; @POSTS=(); $FOOTER=""; $COUNT=0; foreach my $entry (@_) { &ingest($entry); } for(my $i=0; $i<$COUNT; $i++) { if(!exists($POSTS[$i])) { my($begin); for($begin=$i; !exists($POSTS[$i+1]) && $i<$COUNT; $i++) { $posts++; $total++; } if($i==$begin) { $POSTS[$i]=&missing_post($i); } else { $POSTS[$i]=&missing_post("$begin-$i"); push(@missing, "$begin-$i"); } $posts++; } $total++; } if($total) { printf("%s, Total: %d, Coverage: %d%%, Missing: %s\n", $META{'path'}, $total, (1-$posts/$total)*100, join(' ', @missing) || 'None'); } else { printf("%s, Total: %d\n", $META{'path'}, $total); } File::Path::make_path($META{'path'}, { 'chmod' => 0755 }); open($html, '>', join('/', $META{'path'}, 'index.html')); print $html $HEADER; print $html @POSTS; print $html $FOOTER; close($html); } if($ARGV[0] =~ m/^-+h/i) { pod2usage(-verbose => 2, -exitval => 0); } elsif(! -d $ARGV[0]) { pod2usage(-verbose => 1, -exitval => 0); } find(sub { $File::Find::prune=1 if(m/^assets$/); $File::Find::prune=1 if(m/^topic$/); if(m/(\d+)\s+.*\.html$/) { push(@{$TOPICS{$1}}, $File::Find::name); $SEARCH_PATH{$File::Find::dir}=1; } }, @ARGV); foreach my $topic (sort({ $a <=> $b } keys(%TOPICS))) { &process(sort(@{$TOPICS{$topic}})); } =head1 NOTES B<forum_archive> is basically a conglomeration of regular expressions. This is by no means the best way to manage and manipulate complext HTML files. However, given the static nature of this content and its relative complexity, using regular expressions requires a substantially smaller code base and interpretation of the original source files. Essentially, in this case, it is too much easier to strip out the junk you know you don't want than to understand the entire document schema fully enough to make the meaningful changes the right way. =pod -
@lia Line 344 does have to do with avatars
s|(?<= component="user/picture" data-uid="\d{1,5}" src=")([^"]+)|&avatar($1)|meg;That should be OK. Maybe the version of perl you are using has an issue with variable width look-behind, but I purposely used
\d{1,5}instead of\d+so it wouldn't be infinite (which should cause an issue).What version of perl
perl -vdo you have?Edit: misspelled "width"
-
@biell Look-behind was the message it gave, well caught.
I'm using Strawberry Perl 5.32.1.1-64bit on a Windows10 machineLooks like my version of perl doesn't work with either. Gave
\d+aa shot and it failed to run. What version do you run and I'll see if I can use that. Might explain why timestamps didn't load either :3 -
@lia said in Organising the Archive:
@biell Look-behind was the message it gave, well caught.
I'm using Strawberry Perl 5.32.1.1-64bit on a Windows10 machineLooks like my version of perl doesn't work with either. Gave
\d+aa shot and it failed to run. What version do you run and I'll see if I can use that. Might explain why timestamps didn't load either :3virtualized/containerized i hope. with a proxy. @biell
XR's got what plants crave!