Organising the Archive
-
@notsure
On the list todo :)
Done
-
@lia I have yet again proved that it takes 20% of the time to do the first 80% of the work, and 80% of the time to do the last 20% of the work.
Give this a shot, extract it to the document root:
https://drive.google.com/file/d/1we2wIcMRgP5t8K2laDzwHo-1xOHlxH0D/view
It will create /topic and /assets directory structures that mimic how a live nodebb is supposed to look. I used an "index.html" file so the URL bar will be very close looking to what you would see on a live system.
If something major doesn't look right, then I probably just don't have it configured right for how your webserver is setup. If it does look good, go through it and let me know of what other things you would like to see changed.
I am assuming you aren't going to mirror people pages, right? I removed all the people page references, but left them looking like links (you just can't click them anymore).
It looks like your webserver is ubuntu, do you have shell access? If so, it should have perl, and so I can just send you the script once you are done and you can run it against all the other pages.
-
Thanks @biell :)
It looks great and surprising doesn't take an age to load as I worried it might since that was a 2000+ post long topic. Having the directory structure like that makes sense, I did have to move the assets into the same directory as index for it to work then add a "." before /assets/ to get index to use a relative path which did the job.
am assuming you aren't going to mirror people pages
Correct, I did consider it but it seemed like a lot of work for no real benefit since the user pages would literally be a picture in time with no ability to pull posts together without me actually just building a database.
Was it possible to have the script spit out a txt for missing post IDs or was that a pain to impliment?
It looks like your webserver is ubuntu, do you have shell access?
I do, but I intend to repair files locally on the Windows machine then one by one add them to the archive so that I can speed up the tweaks I do in VS.
Thank you so much for doing this. I can't put into words how much this helps <3
-
@lia You shouldn't have to move anything, and using a shared /assets across all posts should ensure that images like avatar's which are used all over only exist once. That is good for your disk space, and good for page load times, as people only have to keep the image in cache once.
Did you extract at the document root of the web server. I set things up that way, but I am now realizing that is dumb to rely on that, and I can do relative links. I will make all the links relative, and you won't have to edit move anything. I will get you a new version tomorrow with that modified.
Are there any other changes you are trying to make, I can incorporate those also. After that, I can send you the perl script and you can run it for yourself. Or, if you prefer, we can create a pipeline whereby you send me a zip, I filter it, then send you back the updated zip.
-
@biell said in Organising the Archive:
After that, I can send you the perl script and you can run it for yourself. Or, if you prefer, we can create a pipeline whereby you send me a zip, I filter it, then send you back the updated zip.

-
@biell That's a better idea, keeping avatars in a common assets directory.
I was hesitant on keeping all post images in one place as it looks like the early forum didn't rename images to prevent clashing image names. If they were all merged a handful may get overwritten so at least for post images storing them in their own topic directory makes sense since there is almost no cross pollination in assets.
I haven't put it on the server yet, it's only on my PC however I intend on keeping it all in the site directory so I don't have to grant permissions outside it.
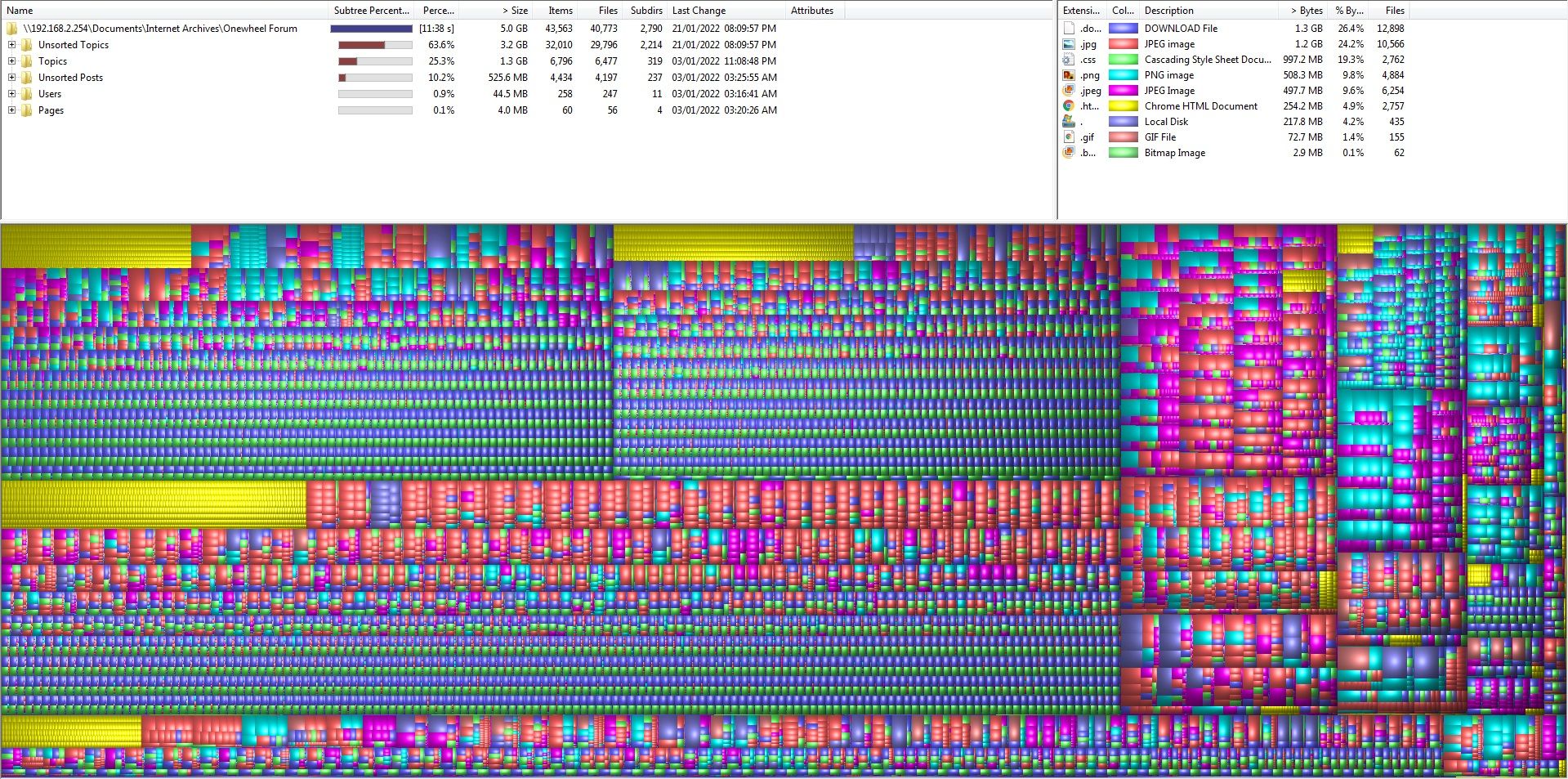
I've only made a minor adjustment to the header and added back a section that helped with mobile compatibility. If you view Topic 2 on the current build you can see it behaves better on there and Mobile (before it was hard to see and the banner got in the way). The <div class="topic-header"> appears to be what holds the element that stays on the page which when removed breaks that and makes mobile a nightmare.
Below is the full HTML for the top section of the page before the post data begins. if that helps.
<!DOCTYPE html> <title>Welcome to the Onewheel forum! | Onewheel Forum</title> <link rel="stylesheet" type="text/css" href="./resources/client-darkly.css"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <meta name="content-type" content="text/html; charset=UTF-8"> <meta name="apple-mobile-web-app-capable" content="yes"> <meta name="mobile-web-app-capable" content="yes"> <meta property="og:site_name" content="Onewheel Forum"> <link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/font-awesome/4.7.0/css/font-awesome.min.css"> <link rel="icon" href="./resources/OWForumArchiveIcon.png"> <main id="panel" class="slideout-panel" style="padding-top: 1px;"> <nav class="navbar navbar-default navbar-fixed-top header" id="header-menu" component="navbar"> <div class="container"> <div class="navbar-header"> <a href="http://archive.owforum.co.uk"> <img alt="The Archive homepage" src="./resources/OWForumArchive.png" height="60"> </a> </div> <div class="navbar-header pull-right"> <p class="text-right" style="padding-top: 10px"> This page is an archived copy of the old Onewheel Forum. </p> </div> </div> </nav> <div class="container" id="content"> <div data-widget-area="header"> </div> <div class="row"> <div class="topic col-lg-12"> <div class="topic-header"> <h1 component="post/header" class="" itemprop="name" style="padding-top: 50px;"> <span class="topic-title" component="topic/title"> <span component="topic/labels"> <i component="topic/pinned" class="fa fa-thumb-tack " title="Pinned"></i> <i component="topic/locked" class="fa fa-lock " title="Locked"></i> <i class="fa fa-arrow-circle-right hidden" title="Moved"></i> </span> Welcome to the Onewheel forum! </span> </h1> <div class="topic-info clearfix"> <div class="category-item inline-block"> <div role="presentation" class="icon pull-left" style="background-color: #00487F; color: #ffffff;"> <i class="fa fa-fw fa-list-alt"></i> </div> <a href="#">News & Announcements</a> </div> <div class="tags tag-list inline-block hidden-xs"> </div> <div class="inline-block hidden-xs"> <div class="stats text-muted"> <i class="fa fa-fw fa-user" title="Posters"></i> <span title="1" class="human-readable-number">1</span> </div> <div class="stats text-muted"> <i class="fa fa-fw fa-pencil" title="Posts"></i> <span component="topic/post-count" title="3" class="human-readable-number">3</span> </div> <div class="stats text-muted"> <i class="fa fa-fw fa-eye" title="Views"></i> <span class="human-readable-number" title="8665">8665</span> </div> </div> <a class="hidden-xs" target="_blank" href="https://community.onewheel.com/topic/2.rss"><i class="fa fa-rss-square"></i></a> <div component="topic/browsing-users" class="inline-block hidden-xs"> </div> <div class="topic-main-buttons pull-right inline-block"> <span class="loading-indicator btn pull-left hidden" done="0"> <span class="hidden-xs">Loading More Posts</span> <i class="fa fa-refresh fa-spin"></i> </span> </div> </div> </div>Other than that I think it's all good. Did the script manage to spit out missing post IDs?
Wondering if I make a template post could we have the script just insert it in place to both acknowledge it's missing and also where to submit the post if it's later found elsewhere. I can go in later and piece those few missing ones together in VS and remove my template.I'm happy to run the script if you prefer. Whatever you prefer since it's your script, this is the volume of data I'm working with just to give you an idea so I'm happy to run it if that looks like a nightmare xD It certainly was to manually scrape from google cache lmao.
-
@lia I should be correcting all the media file names so they don't overlap, but you make an excellent point. Since I am using an index.html, why not put all the media with the post. The likelihood of an uploaded image being used multiple times is --in stark contrast to avatars-- highly unlikely. I have moved that uploaded media next to the post as you suggest.
If you can put perl on your PC (there are Windows Perl distributions, and of course, WSL may be an option for you too), then please have at it. If this looks good, I will finish the documentation and send it over. When reviewing someone else's code, it is
I think I have the header the way you want, it does look better now from a phone resolution.
I now also have the script spitting out missing post IDs, followed by a coverage percent, so you know how close to 100% you are. I have inserted a post for missing content as you suggested, please update as you see fit.
This script can be run at any time from the source material to recreate the post. So, once you have downloaded more content, we can just rerun it and it will pick up all the information, including the new stuff. This is why I am trying to get all the things you want into the script, so you wouldn't have to hand-edit a second time.
I couldn't get Google web cache to show me the archive posts. If you have any information you can provide about how you pulled down the content so far, there is a possibility I could automate filling in the gaps.
A new version is available here:
https://drive.google.com/file/d/17w2d7AOOejXp7UjTqfROTTofHtI_l3in/view?usp=sharing -
@biell That looks perfect, the missing post bit is great too. Thanks for implementing it :)
I should be able to install PERL. Worst case I can fire up a VM for whatever OS I need to run it.
@biell said in Organising the Archive:
If you have any information you can provide about how you pulled down the content so far
The way I did it was really messy and manual. I spent weeks going to google and entering "site:community.onewheel.com/topic/XXXXX". I'd manually have to increment my search +1 to search whatever google had for that topic. Once I got results I'd click the options next to the link and try to browse a cache if it existed, Ctrl+S then add the page ID the URL gave in brackets to the file name. With nearly 10000 topic ID's at the time of the forum closing it took me forever D: After 10-20 searches google would make me do a captcha to check I wasn't a robot which made things slower. Pain.jpg >.> I did it this way because google did a cache a day or 2 just before the site got replaced with the maintenance message and was worried if I didn't act fast they'd send the cache robot to update itself again and lose all the data. Didn't think I had time t learn how to automate this.
.
I'll get to work uploading it soon, would you like a name or some sort of credit placed anywhere on the archive for helping resolve this mammoth part of the job?
-
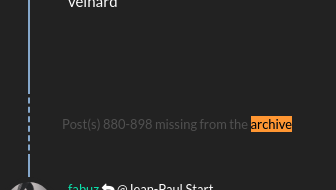
@lia I thought of another way of doing the missing post, I like it better. What do you think?
-
@biell That's a much better idea. Good thinking :)
I think there might be a few topics where there are a lot of missing posts so that'll help keep it tidy. -
@lia I am glad you did the work when you did, I tried to do a search the way you describe, and Google doesn't have anything. I tried archive.org and did have much luck there past the first page of results.
I don't need any credit.
BTW, this is what running it will look like for the missing articles and coverage percentage:
$ ./forum_archive topic-20 topic/20/france-onewheel-riders : Missing: 83-136 160-169 249-253 274-281 302-339 382-397 514-545 566-588 687-704 880-898 919 940-943 1040-1041 1062-1072 1110-1111 1244-1253 1287-1312 1333-1339 1360-1374 1395-1412 1455-1459 1487-1492 1522-1528 1560-1571 1682 1732-1734 1797-1800 1834-1842 1902-1996 2017-2025 2093-2101 2128-2139 2176-2193 2228-2238 2272-2275 Coverage: 76% $So, if you have a bunch of folders all containing different topics under a single location, you could just run
forum_archive *and it will loop through each, putting all the data under eitherassetsortopicdepending on the data type.I will make the change for the simpler, less obtrusive missing posts method. I will take a pass through the script, clean up the code a bit, add some documentation, and send it over. The script is short, so even not knowing perl you would be able to read through it before running it, to verify you trust it. It should also be easy to change the broken image link icon if you don't like the one I selected.
-
@biell I can find a few things on archive.org but I found searching with it was extra tedious so I'm planning to find the rest if I can through it since that wasn't time sensitive.
If you're sure, thank you so much for the effort you put in <3
That's really helpful. I'll cast an eye through it, might learn a thing or two as I do :)
-
@lia The Perl script can be found here:
https://drive.google.com/file/d/1UoQaB3_wzojQOilSgkt-TNamNYDRqwLU/view?usp=sharing
Basically, I assume you have a folder somewhere and it contains folders, each of which look like the zip file you sent me. If so, you could litterally just run
forum_archive *in that location and it would read through all the sub-folders, then neatly pack everything under aassetsand atopicfolder, with you just having to move those two directory structures into your webserver's DocRoot.I don't think I used any Perl modules you wouldn't find standard.
Please let me know if you have any questions.
-
@biell Thank you :)
I'll hopefully give it a whirl this weekend since it's raining here anyway so plenty of indoor time to work with.Thank you for making this :)
-
@biell Finally found time to give it a whirl. Not sure if it's Windows or what I'm doing but I can't get it to work properly. Probably something I'm doing no doubt >.>
Using StrawberryPerl on a Windows10 Laptop.
Renamed the file to forum_archive.pl as windows couldn't figure out what to do with it in cmd.
Script exists in a directory (Forum) and inside with the script is a folder called RAW where I'm dumping all the cache scrapings.
Here is a Tree of that if it's easier to follow (note 2 and 22 were separated for testing later).
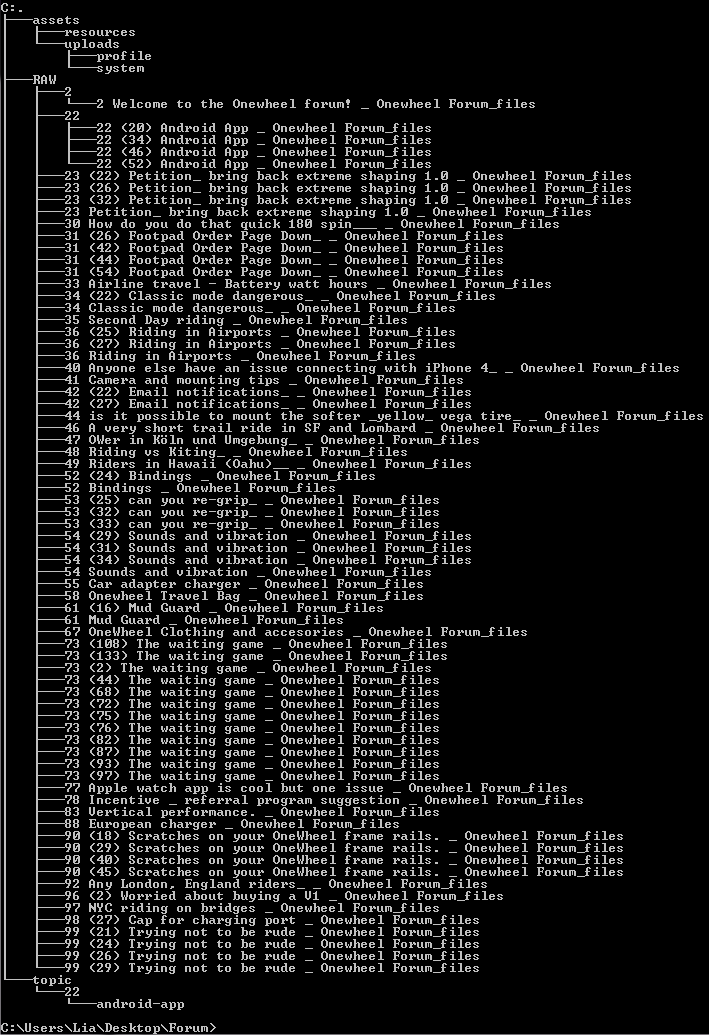
If I run "forum_archive.pl *" it complains it wants a specific directory.

"forum_archive.pl RAW" runs it but then states an illegal division by zero on line 451 occurred when trying to give the "missing" field.

If I place the topics in their own directory rather than all in the same one it runs and completes but doesn't move any of the images to the resources directory.

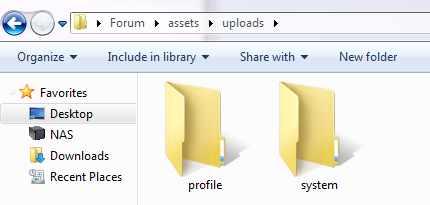
If a topic only has a single entry to run it gives the division by zero error again. I assume this might be what is causing the "forum_archive.pl RAW" command to fail.

I've zipped up exactly what I have currently with a selection of files in RAW. I've left topic 2 and 22 as separated so you can see what worked and what didn't.
Forum.zip -
@lia I will look into this. I see a couple things. Firstly, I made a couple mistakes because I only had a single topic to test against (oops). Second, I was expecting everything to be organized like your "2" and "22" directories, I may have to do some finagling to handle multiple topics in the same directory.
Also, I see that topic "2" is causing an issue, so I will work through that now that I have more data.
Please just give me a few days to iron this out. Sorry about that. I may need some consistency between either the organization like topic 22 or topic 23.
-
@biell said in Organising the Archive:
Firstly, I made a couple mistakes
What??? Mistakes in software??? This can not be!!! /s ... I'm a retired software engineer :D
-
@biell Thank you :) no rush on it at all, been caught up in a few things so haven’t been able to focus on much.
My fault for not providing more test data, a single example was a bit dim of me to provide.
-
i had a post about my flightfin switch install. is that saved in the archive somewhere by any chance?
-
@swinefeaster One of the ones I specifically looked for when I started the project. I have it.
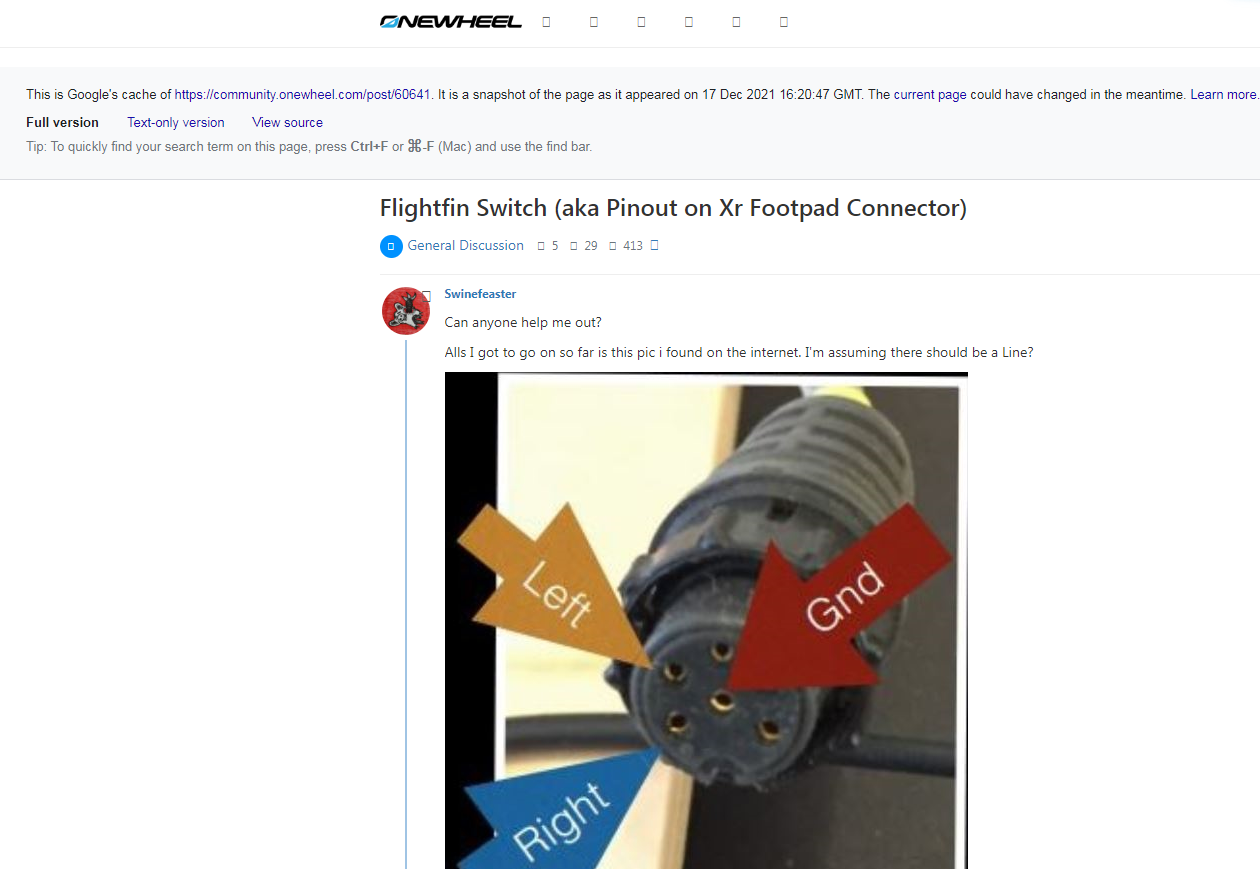
Shall be up soon, I might manually do this one since it's only 29 posts long.