Organising the Archive
-
@notsure Thanks for the input :) I personally don't think I'll write a script for this and hand repair them since it's well out of my toolset. That said I may later take a swing at it now that I'm sort of getting to grips with Visual Studio.
For the one that I've merged myself the individual posts are contained within a list tag "<li>...</li>" each.
The post ID is a bit buried though as "data-index".
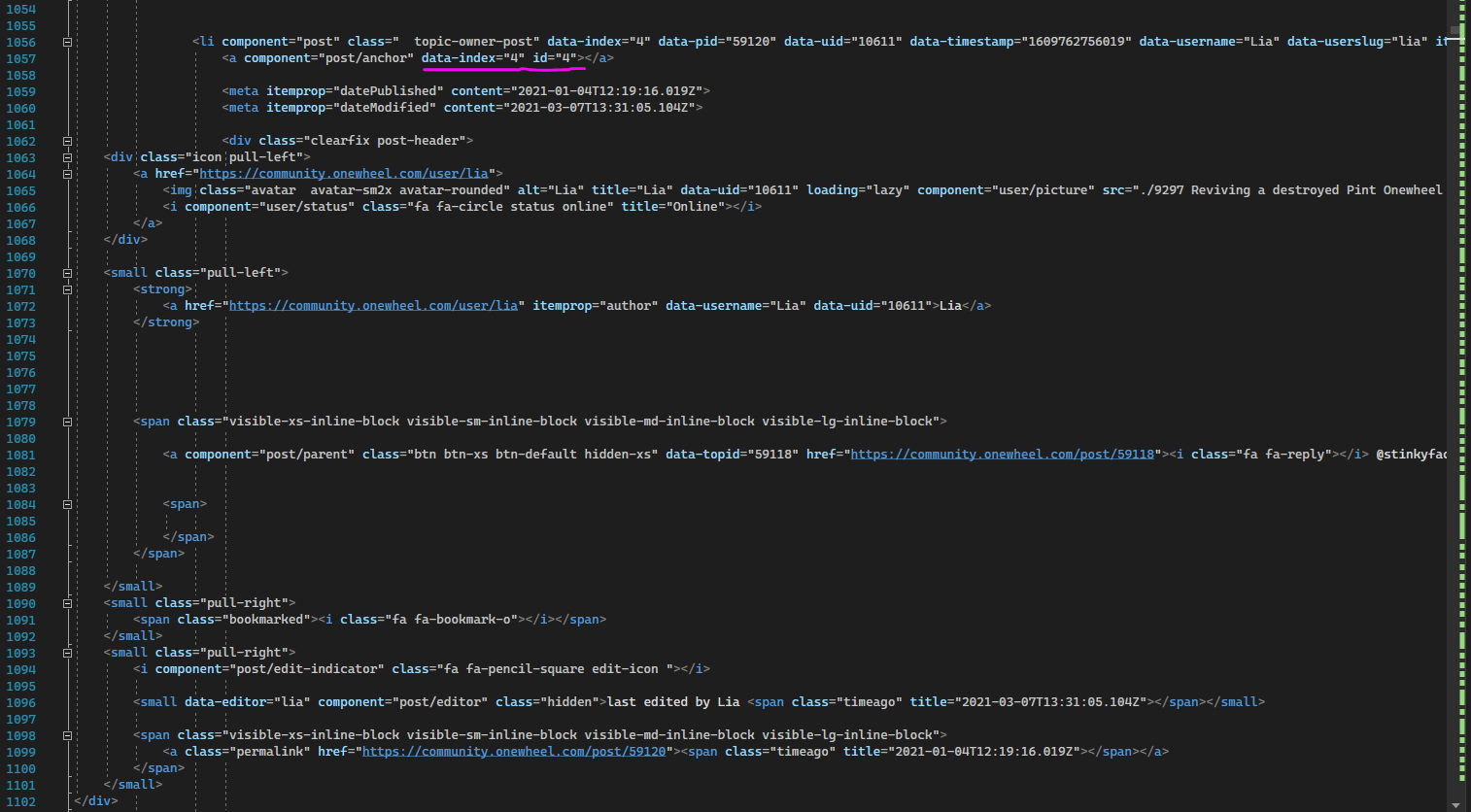
I imagine the script would have to look through a page for "data-index=" then expand it's selection between the previous <li> tag and the closing </li> tag. However it would need to lookout for additional list tags within the document which complicates matters.
I found it easier to close all tags then copy the 20 or so blocks into the "master" document.
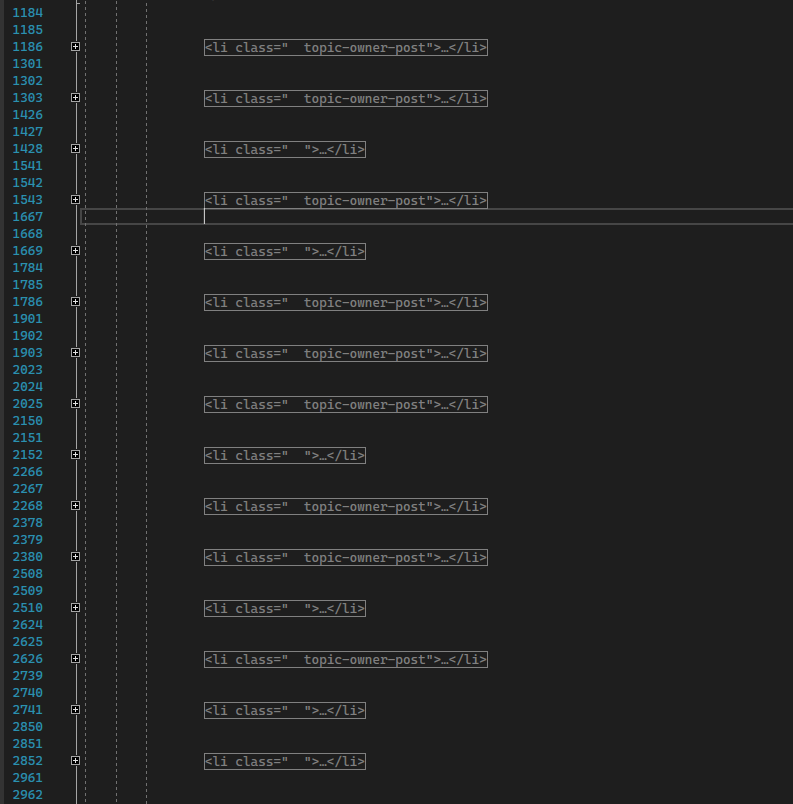
For the France topic and a few others I might separate some into pages since they're far too big to not destroy someones browser.
@notsure said in Organising the Archive:
users r so nitpicky! just eat this wall of text u ape!
My eyes snapped to this when I saw the wall. I am at heart illiterate ;)
-
@lia said in Organising the Archive:
For the one that I've merged myself
nodebb uses a redis distribution for its database. that means ur not done learning perusing doc notes yet lol... redis is a database. it's how nodebb stores its data. u learn redis, u learn nodebb.
XR's got what plants crave!
-
@lia I really like the background, I think you should keep it.
If I understand you, the pages you have (e.g. France riders) are each a subset of comments/replies (up to 20) and you need to stitch it back together into a single strand using overlapping context. If so, this is actually very similar to how DNA sequencers work (just a fun aside).
If that is what you need, and you were able to share the files you have, I should be able to pretty easily reconstruct a single file sequence. If you had a google drive or something and uploaded an example like the France riders one as a zip or something, I should be able to write a relatively straightforward script to stitch it all back together and upload back a single HTML file.
If that worked, we could figure out a process to run through the entire archive. In the process, I could also make any HTML header/footer/etc. alterations you would want.
-
@biell she's concerned about embedded bugs in the source. i would be too considering she'd be hosting it without knowledge of how to maintain it. if she could iterate thru that html, pull proxy user ids n store the relevant data, she could simply lock those ids n reduce maintenance. in my humble opinion. what do u think?
-
@notsure That bit's fine, since I'm not rebuilding the site but just fixing the HTML output that it spits out since that's what I have saved. As such I'll try to strip out any calls for server dependencies so it's not calling to a site that doesn't exist.
I did consider building a replica nodebb install then stripping and entering data into the database to replicate the old server but that sounded way too involved and didn't feel right.
@biell Thanks :)
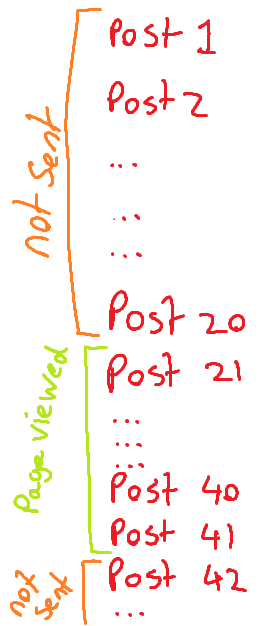
It's a render someone did of the scene from Raiders Of The Lost Arc and I just added some OW stuff on top. If I plan to use it I'll see if I can ask the artist if they're okay with it and if they want any credit added anywhere since their signature gets lopped off at the side D:That's pretty much it. The site seemed to have a script to see what part of the page you were viewing then only send that data. Excuse the crude doodle.
I can look at putting one of them on a GDrive later on if you're up for it :) Thanks for the offer, no worry if it's too much effort though, really appreciate the support.
-
@lia said in Organising the Archive:
I did consider building a replica nodebb install then stripping and entering data into the database to replicate the old server but that sounded way too involved and didn't feel right.
ppl could reclaim them later. it would look and act like the regular forum. thats why i recommended it. it would be a seamless integration. u click on users, n see their prior statements. can visit their threads and see the others... but its ur forum! im just being fancy.
XR's got what plants crave!
-
@notsure Totally get it, I'd love to do it that way and re-assign posts back to the OG authors but I don't have the confidence to edit a live database and not bork it up. Manipulating the HTML seems more attainable for me at least.
It also sort of feels wrong. Not illegal but really weird to be handling abandoned data and manipulate it in that way rather than just rebuilding the displayed output and putting it on display. Feels more like an archive this way and probably less of a target for FM if I'm simply hosting the frontend instead of fiddling with the data. I'm not the British Museum after all ;)
With this method I can keep the 2 sites separate. Old and New where the old one is a picture in time while the new one is where everything is now. Solves possible issues with incompatibilities and possibly corrupting the older pages with updates and plugins.
-
-
@biell Uploaded the France riders I managed to get, should be plenty in there to really give a script something to chew on if you can get something to function.
[redacted]
Don't worry if you can't get it to work, really appreciate the offer to take a look.
-
@notsure I agree, this would be the reason to try and render the pages as static HTML, then there should be no server-side concerns.
-
@lia Thanks, I downloaded it and was expecting to find HTML files also, but all I seem to have ones ancillary/media files. Did I miss something. You will have to excuse me, I have been supporting a change this weekend and it didn't go well, so I have been working for about 12 hours so far today.
-
@biell Oh balls it didn’t compress the actual html links. I’ll fix that in the morning, sorry about that D:
Hope what you’re working on goes well, I know the feeling getting stuck on a work project that just doesn’t go anywhere.
-
@biell There we go, put all the files in this time (and I checked it again just in case lol).
20 FRANCE OneWheel Riders _ Onewheel Forum_files.zipThe HTML files have a corresponding folder that contains images and other dependencies that was downloaded when I saved the pages.
For the one I repaired I just merged all the folders into 1 then made sure all the references to the files in the master HTML were pointing at the master folder and not the individual ones if that makes sense.
-
*clears throat *
Haven't given the site an SSL certificate yet buuuuut...
archive.owforum.co.uk
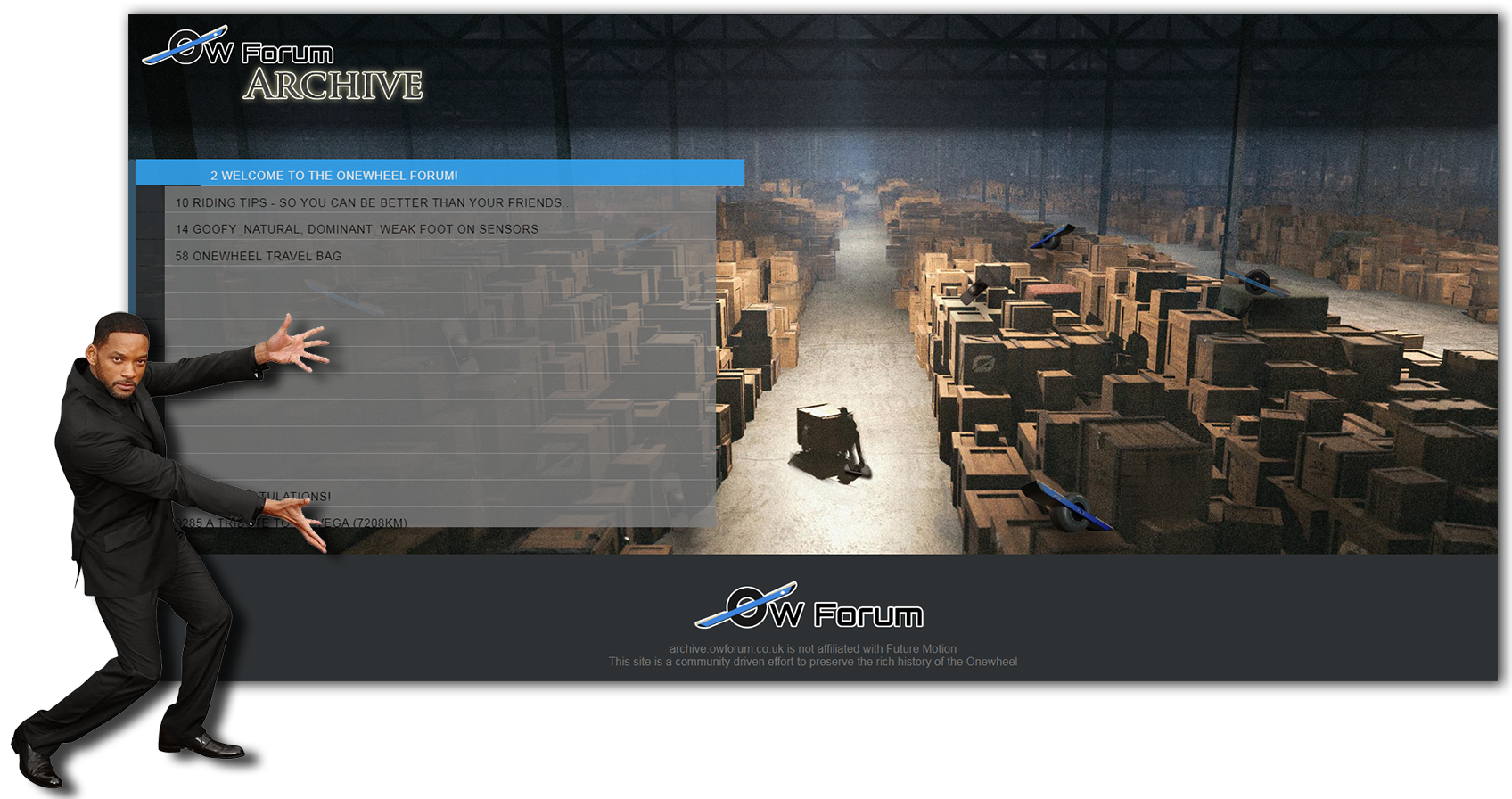
Totally got Will Smith to show this one off for me. Thx Will x
.
Seems to work fine on mobile too so far. I'm tempted to put an iframe window on the right side to preview the clicked topic but need to figure out how to do that.
For now any feedback would be great (be gentle lol).
To Do List
- Add a custom header to all archived topics to return to the main page.
- Maaaaybe figure out an okay-ish search facility
- Git gud
-
@lia -- I am in awe!!! -- of your drive, of your dedication, and of your abilities!!!
-
@s-leon Thank you <3
You all give me the strength and desire to do all of this. I can't think of anything else that would have me attempt even a fraction of this.
-
Pinned by
 Lia
Lia
-
@lia So, this should be pretty easy. The posts are all contained within a single giant unordered list. Each post is a list item, and there is metadata with a "data-index". So, both getting the correct post order and deduplicating entries from the different files will be a breeze.
All the files media/aux files under the _files structure are identical across all posts by name (e.g. 2170-profileimg.jpg is always the same picture).
If you are still interested, it would only take an hour or two to write the program, and then it could stitch all of this together. I would write it in perl, because I'm old. So, either you could upload zip files like this or I can easilly write it so the most basic perl install will work for you to run it yourself.
I can also program to rewrite the header to clean it up, for example I could remove the "Register" and "Login" links. I can also remove the text added by Google Cache, if you would like.
I can also remove the upvote/downvote links while I am at it, if you want. Or, I can completely remove that section, including the vote-count.
Let me know how you want it, I can then write version 1, send you the output, and we can tweek from there. But, this should all be very straight forward.
-
@biell music to my ears, removing those bits will be fine as I plan to go in and add a template header that’ll call to some master .css for the rest. Getting all the broken topics together would be a dream.
Would it be possible to have it spit out a txt or something per completed topic of missing post ids? I’ll go in after and add a placeholder list item and later try locating them on archive.org
I think we can keep the up/downvotes, Those might be interesting to see still and I’m working to repair the missing icons and later a way to do the timestamps.
Thanks for taking the time to have a look, will be sure to give you some credit on the archive page for helping simplify this mammoth task.
-
@lia Providing a list of missing posts should be very easy.
If you copy over from the current forum the "/assets" directory structure into an "/assets" in the archive website, then the missing icons should be fixed. From what I can tell, that is where they were, and where I hope for them to be looked for after I de-googleify the pages. Or, if you like, I could try to point the missing assets to this forum.
-
@lia What's wrong with the timestamps? Do you just want them rendered in UTC, or do you want them rendered localtime? If you want it in UTC, I can just hard code it into the page from the metadata and put that in the correct place. If you want it rendered in localtime, I should be able to add a touch of javascript to render that, but it will take longer to get working.