Organising the Archive
-
EDIT : It's done! I can't believe I'm saying it!!!
Totally got Will Smith to show this one off for me. Thx Will x
End of edit, resuming post history :)

86% done with my search of Google cache for "to be destroyed" data. Tools have been suggested but even doing this manually has caused google to flag me as a potential robot. About 1/10 of my searches now ask me for a captcha so I think the automated options may have also hit that snag :(
Since I don't fancy another round today as I did 2000 while at work I figured I'd have a look at how I might rebuild the data.
Why rebuild it? The trouble is NodeBB like a lot of sites won't load everything at once if the page is big enough. Places with "infinite scrolling" will only load the next bits when prompted by you reaching the bottom. Web crawlers like the ones used by archive.org and google's own caching feature just load the page they land on and essentially take a picture in time which doesn't trigger the page to load more. This meant I've had to try and locate results for topics spanning various pages to try collect the pieces.
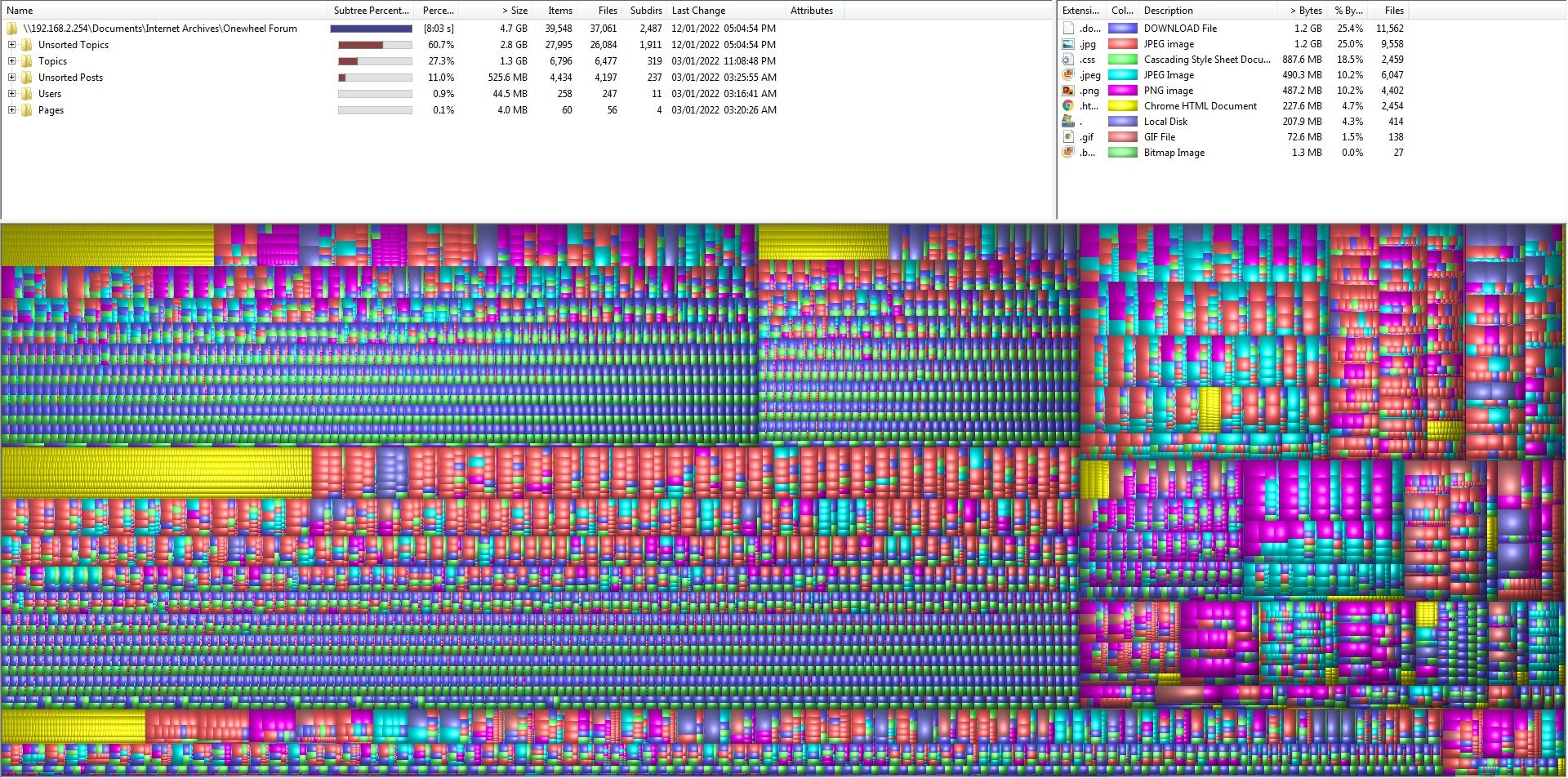
On the upside while looking at the structure of the webpages I was happy to see that each post was it's own node with it containing some pretty crucial data to help piece things together.
The node that contains the topic data has a "data-tid" which will probably mean TopicID since this one was 9297 and matches the URL for the topic. Within this node is sub nodes for each post containing "data-index" and thankfully they're numbered so even if my page tagging is wrong these will be correct.
Along with that is a "data-pid" which refers to a global increment of posts independent of the topic. I counted over 60,000 when looking at some of the last few posts albeit a lot of those are likely deleted spam having seen the vast topic voids while searching followed by complaints of spambots before FM fixed it in the early 6000 topic region.
Lastly one thing I was happy to see was a "data-timestamp". Reason for that is for some reason my captures were not displaying the date/time of posts. I assume the server was meant to decode that and send it out so I'll work on having that fixed when merging together.

How do I merge this together? Manually I can simply copy a node and paste it into a master doc, copy all the source files like images into a single directory and have it display the whole thing. Hopefully pagination is something the source doc handles else I'll have to recreate that...
I do however wish to actually make a script to do this for me. Just dump it all into a directory and have it do the following.
- Sort directories and HTML by topic and bundle collections of the same topic into their own directory.
- Compile all material from X topic into it's own master directory
- Clone HTML from the earliest comment available and have that be the master HTML doc.
- Search the other HTML docs for "data-index" that are not present in the master. When found append to document in order.
- Once all HTML is scanned and copied look check the master if the last "data-index" matches the number of posts that are meant to present.
- Fill all missing "data-index" results with a place holder image and text stating "comment(s) Y ( to Z) are missing from the archive. Please contact Lia if you have located this missing data with". Do this for all missing posts until the last "data-index" for that topic is populated with something.
Not too sure how I'll do it, it'll need to be an offline tool for sure. I've written some kinda complex batch scripts before so maaaaaybe I could write one to do this. I don't code, that said I didn't do a lot of things till I then later did them so we'll see how this goes once I've collected it all. Another cool thing is I can have it log all "successful" and "unsuccessful" attempts to rebuild a certain post within a topic and allow me to actually create some sort of hard number for data we're missing.
With all that done then maybe I can get back to finishing some drawings I was working on before a certain company pulled a plug on something I really liked using >.>
-
Another thing I'd probably want to look at doing is have the links within each archived topic/post actually link to the other archived topics rather than the broken community.onewheel.com ones. That way a somewhat seamless browsing experience might be possible.
Guess that would be a simple case of "find and replace"
community.onewheel.com/topic/<data-tid>withowforum.co.uk/archive/<data-tid>within all of the posts. Subdomain to be decided still.I don't think I can get the search feature to work with it however a Index post pinned to this category with links to each topic would probably be a suitable replacement.
Edit: I want to start the groundwork for this .bat but it's just ticked by midnight and I haven't been getting enough sleep >.> Think the past week I've had on average 4 hours sleep and I'm feeling it.

-
@lia blech! ur gonna fry ur eyeballs with that schema.
darken that up for gods sake! dark reader for chrome is popular.XR's got what plants crave!
-
@notsure IKR D:
I did have something like it once but it kept borking some pages for me >.>Wish web developers just had a dark theme as default for everything. Chrome especially needs to replace the blank white page between loading sites to black too.
-
@lia just click to access. it works very well on most pages and its easy turn off.
-
Lia, are you a borg?
love the lost ark warehouse btwcarving turns all year round
-
@b0ardski Might make things easier if I was. Still wrapping me head around how I'll get a script to interpret and pull what I want. Might be a few days of trial and error with lots of googling (as usual).
Glad you noticed, first thing that came to mind when thinking of an endless warehouse :)
-
i recommend using jupyter notebooks to start. can really quickly test ur code. if ur using javascript, here's something else u might be interested in.
XR's got what plants crave!
-
@notsure Might try python with the first option. I hear it's good for beginners.
Will save me butchering whatever language is used to write batch scripts that I used to do for one off tasks. -
@lia javascript

-
-
9600 topics manually googled with the cached results downloaded if they came up.
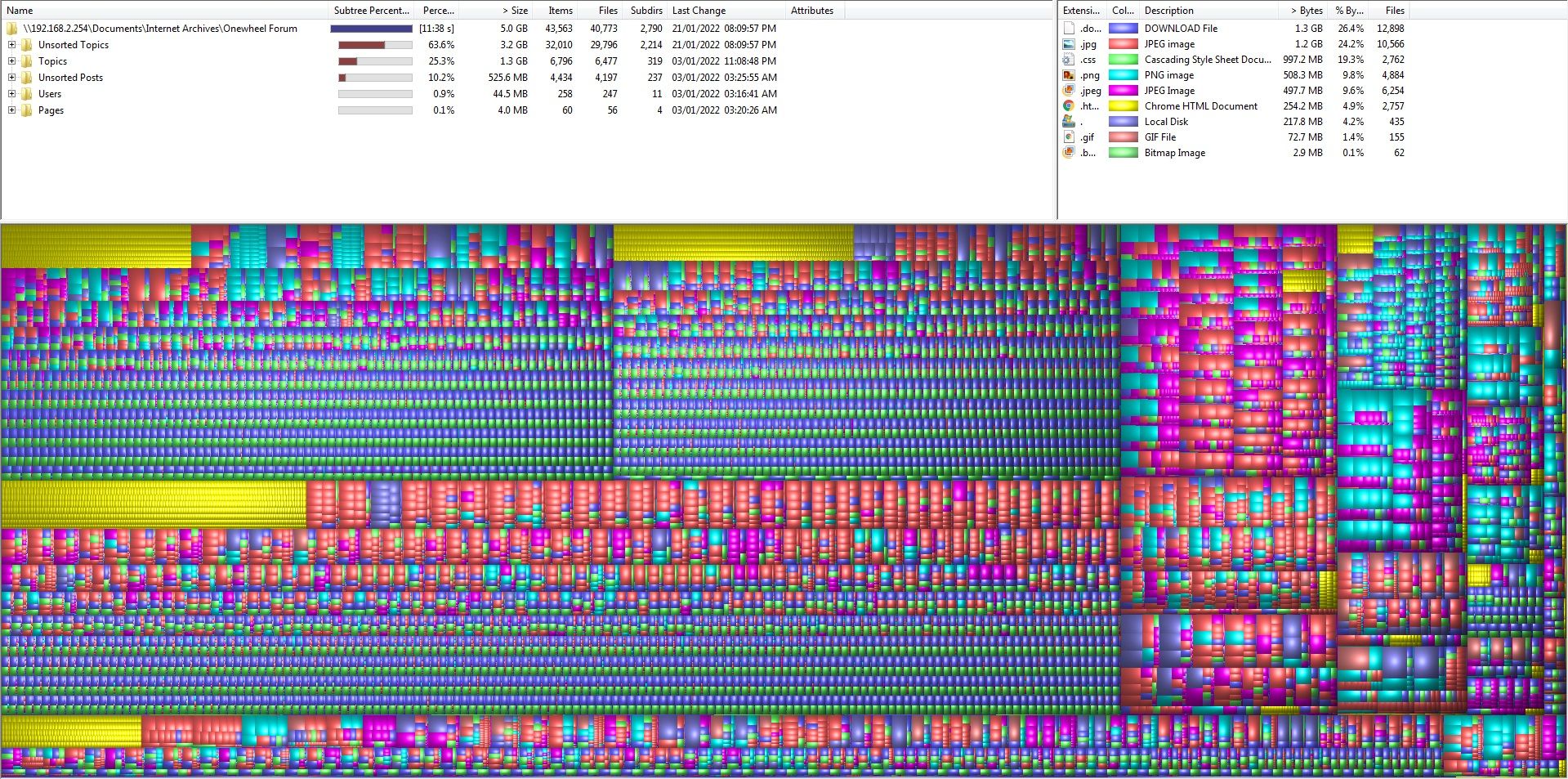
Next up... making a master template to begin merging the pages together.After that I'll host it on the site and setup a way for people to send me missing posts/pages for me to add later. A lot can be found from archive.org but I got the time sensitive stuff for now.
-
@lia said in Organising the Archive:
9600 topics manually googled with the cached results downloaded if they came up.
"um, what exactly do u mean 'bad disk sector'?"
-
Just a little update.
I have manually stitched together the "Reviving a destroyed Pint" thread and looking into a means of hosting it before working through the rest of the threads and creating placeholder elements to occupy posts withing threads that have yet to be found and merged.
Since the pages used to rely on javascript and some other nodebb side dependencies I'm considering hosting the archive on a separate server then routing a subdomain to it, like archive.owforum.co.uk in order to keep both systems isolated.
(edit: corrected the example to an actual subdomain, former example was a subdirectory which takes way more effort to dump on a separate server)Main reason being security. I don't know what holes might get opened by just hosting ripped webpages but I imagine there could be a few so if I keep them separate then at worst the archive gets taken out for a few days before I initiate a backup. That then leaves the new forum safe from that. It also means I'll be able to tweak the archive at any point without accidentally nuking the forum.
-
I am not joking when I say I spent ALL of today trying to make the landing page for the archive ready to make it live with some preliminary pages...
I hate code! (because I'm bad at it) I was going to use some online tools but my caffeine addled brain thought it was up to the challenge. So many tutorials that don't wooooooork adsfgsbglgdg

H O W E V E R...
It pwetty~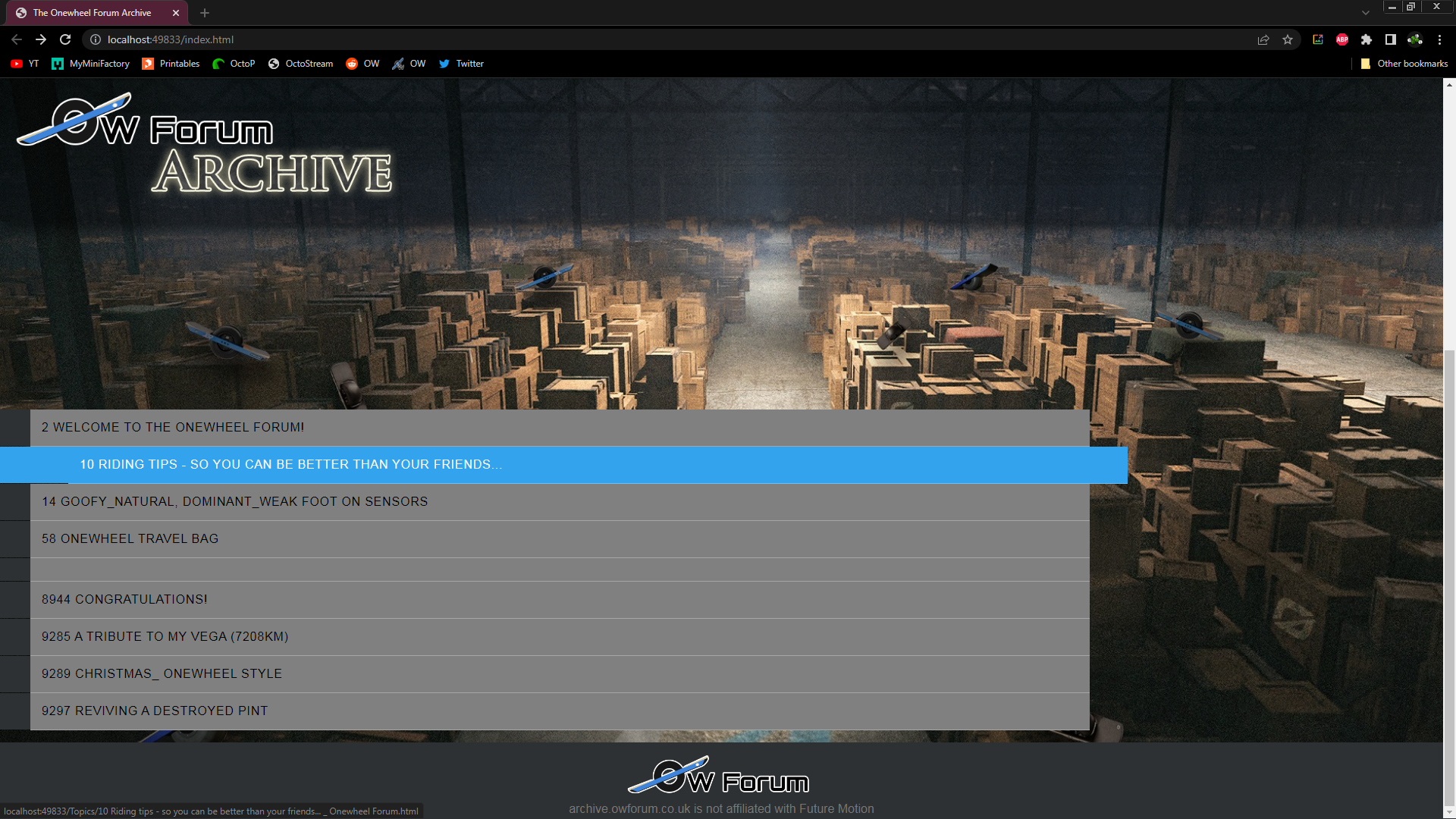
Backdrop isn't staying (maybe), I'd like to get something else but for now it's a fun placeholder.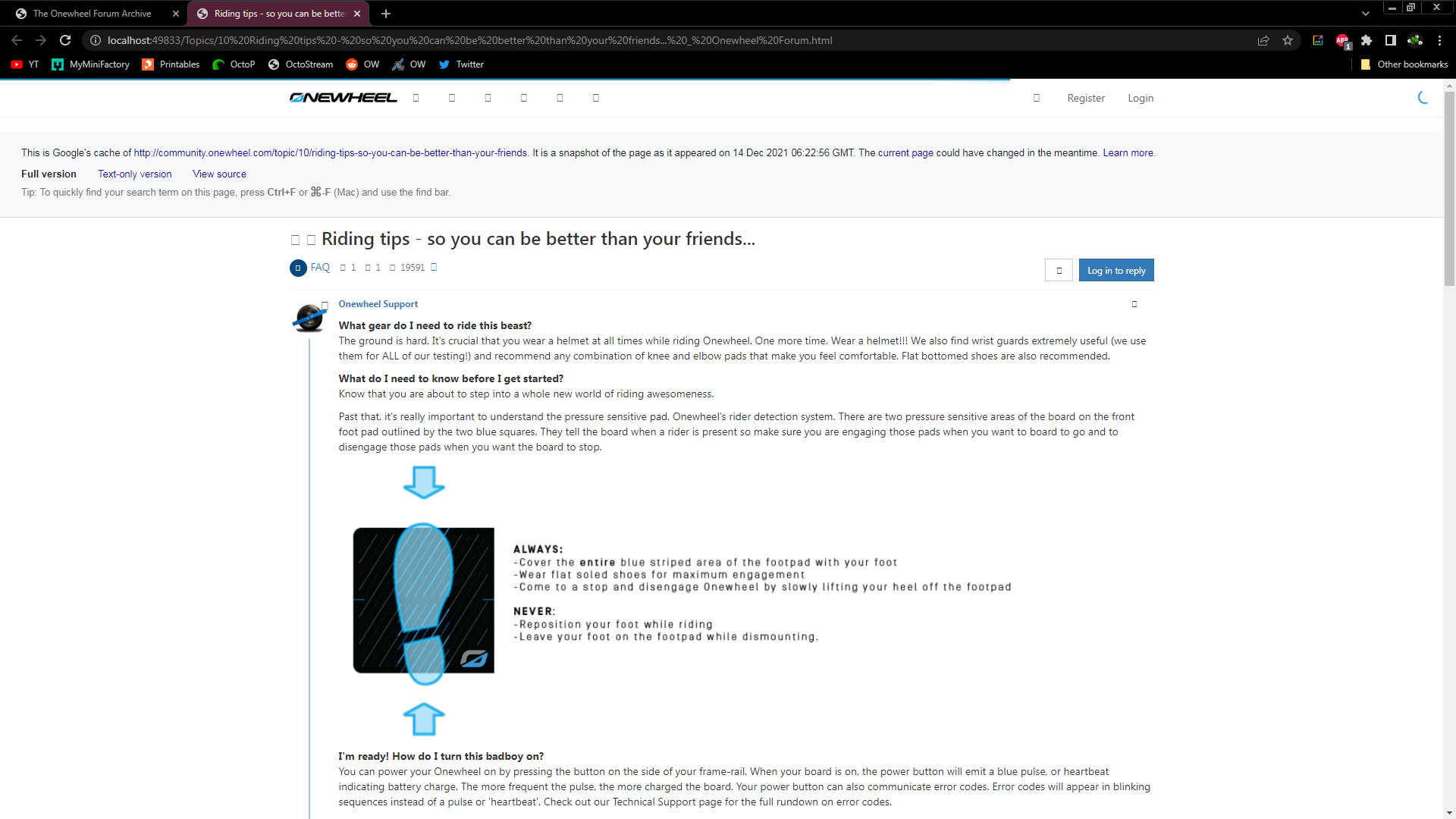
Haven't cleaned this page up yet, considering replacing all the headers with the archive logo that will act as a means to return to the landing page.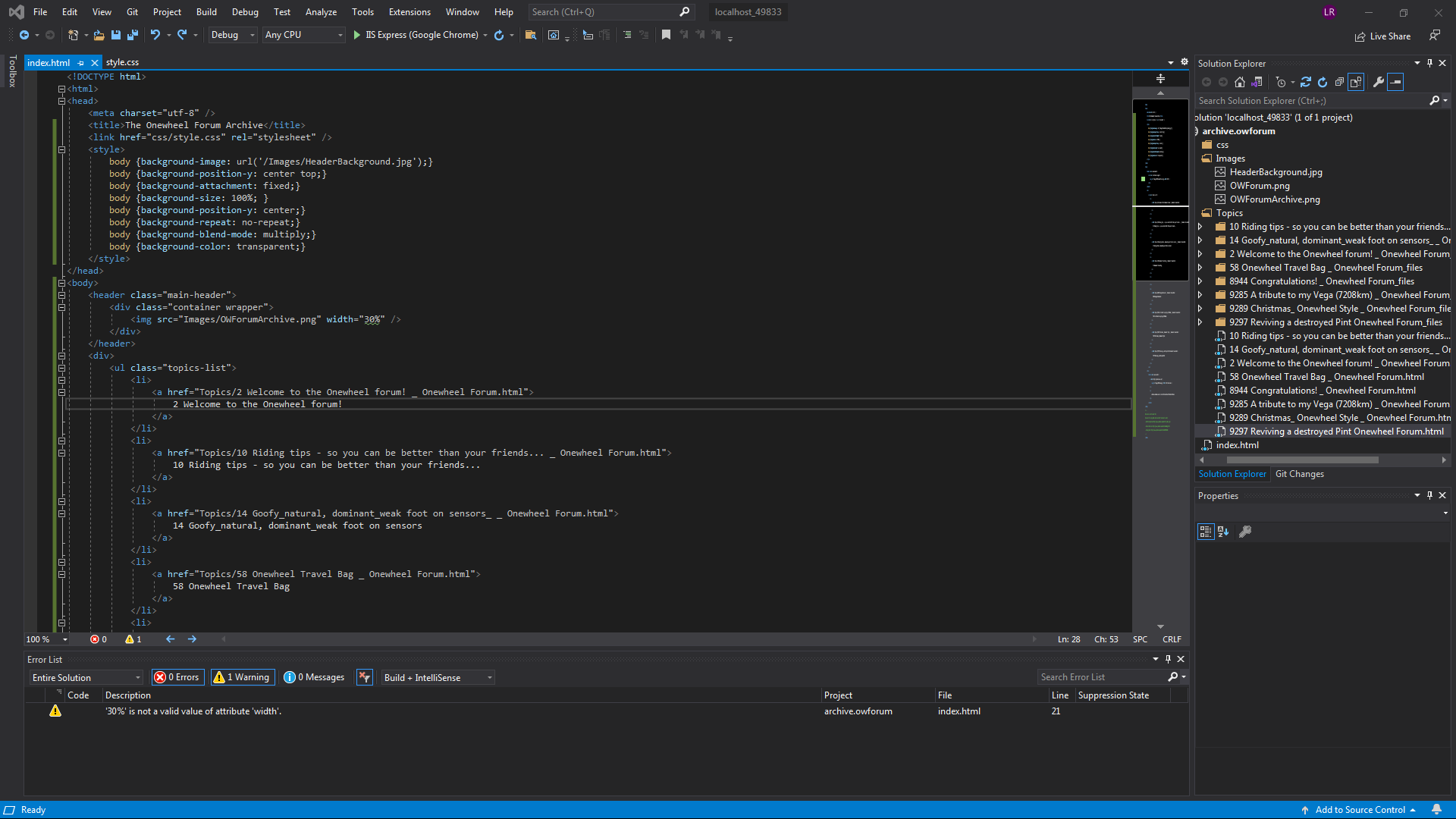
Still plenty more to do to make it usable before I even let it loose on the internet. The actual old pages need a lot of manual tinkering to make them presentable since google butchered them when caching. archive.org didn't do too well either on some but I've figured out what's mostly broken to fix them up.
Big shoutout to @cheppy44 for giving me a boost in motivation which I funnelled into this.
Now I have to get over the prospect of manually reparing the files I got.
All... of them... oh no...

Gonna need more monster. RIP diet.

-
@lia what do you have to do to repair the files?
-
@cheppy44 Depends on the topic, there are 2 issues plaguing some of the topics I got.
First one is all the larger topics are broken into smaller captures. The old forum (and this one since it's the same software) had scripts to only load 20 posts per view that would call to unload and load depending on which way you're scrolling. This meant all the web crawlers would pickup chunks of the forum depending on what post they landed on based on the post ID in the URL.
For instance an early topic (#20) was the France riders that had over 2000 posts. As such I've got various iterations of the topic that occupy different chunks of it.
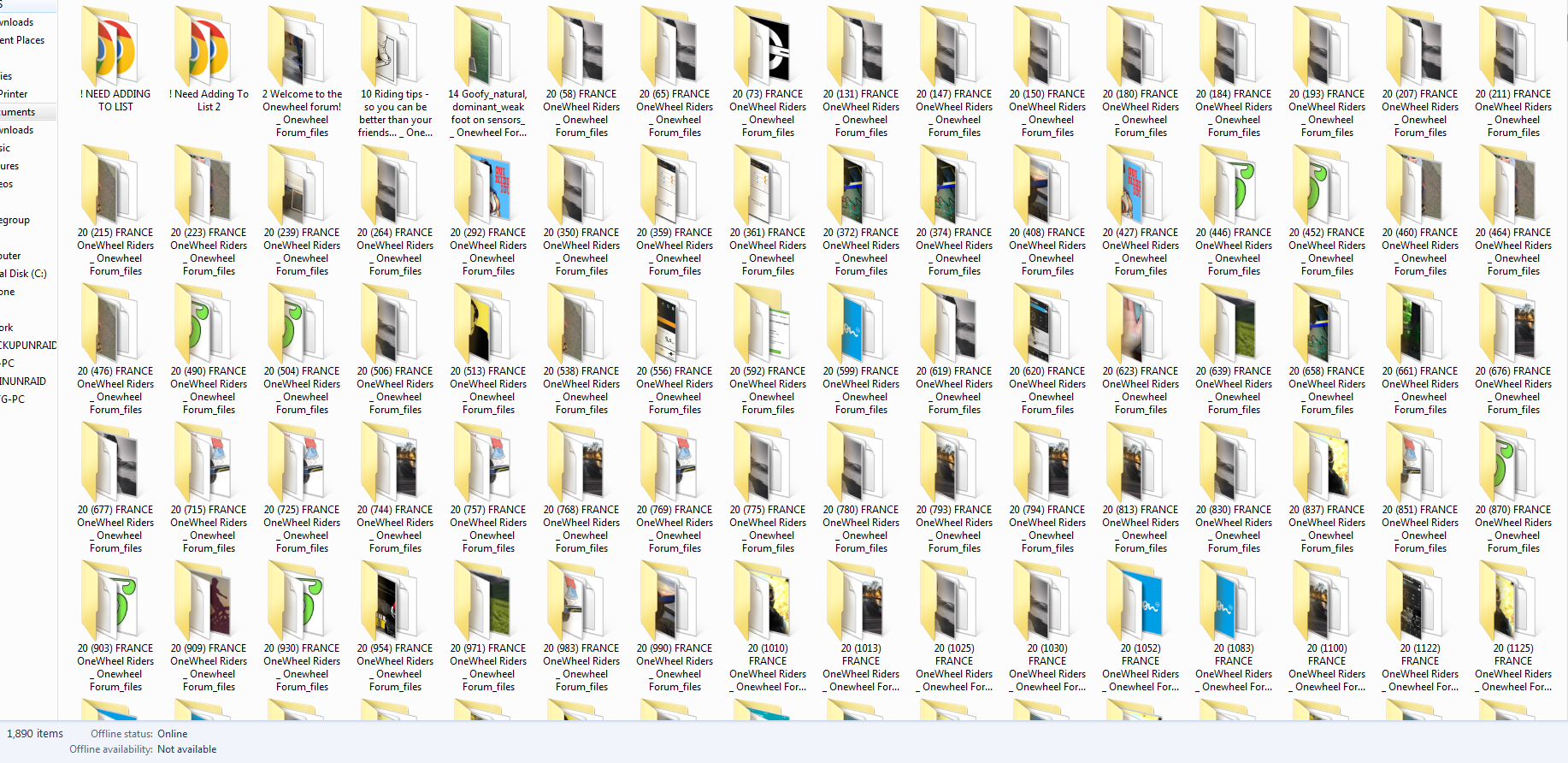
I downloaded the pages, prefixed the name with the topic ID then Post ID in the brackets if it wasn't the first page.
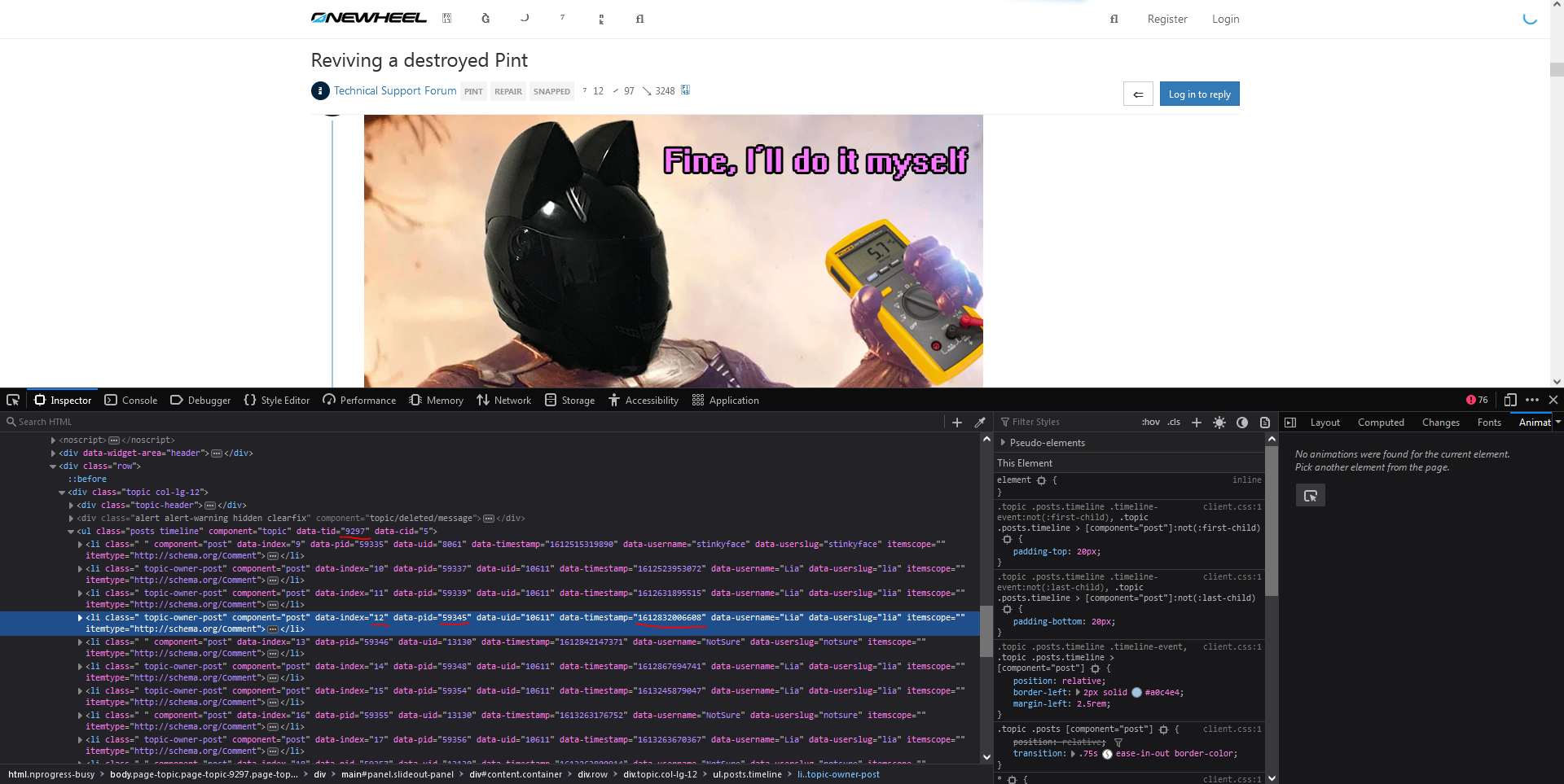
Second issue is sometimes the webcrawler didn't grab a working version of the site so elements end up really scrambled like below.
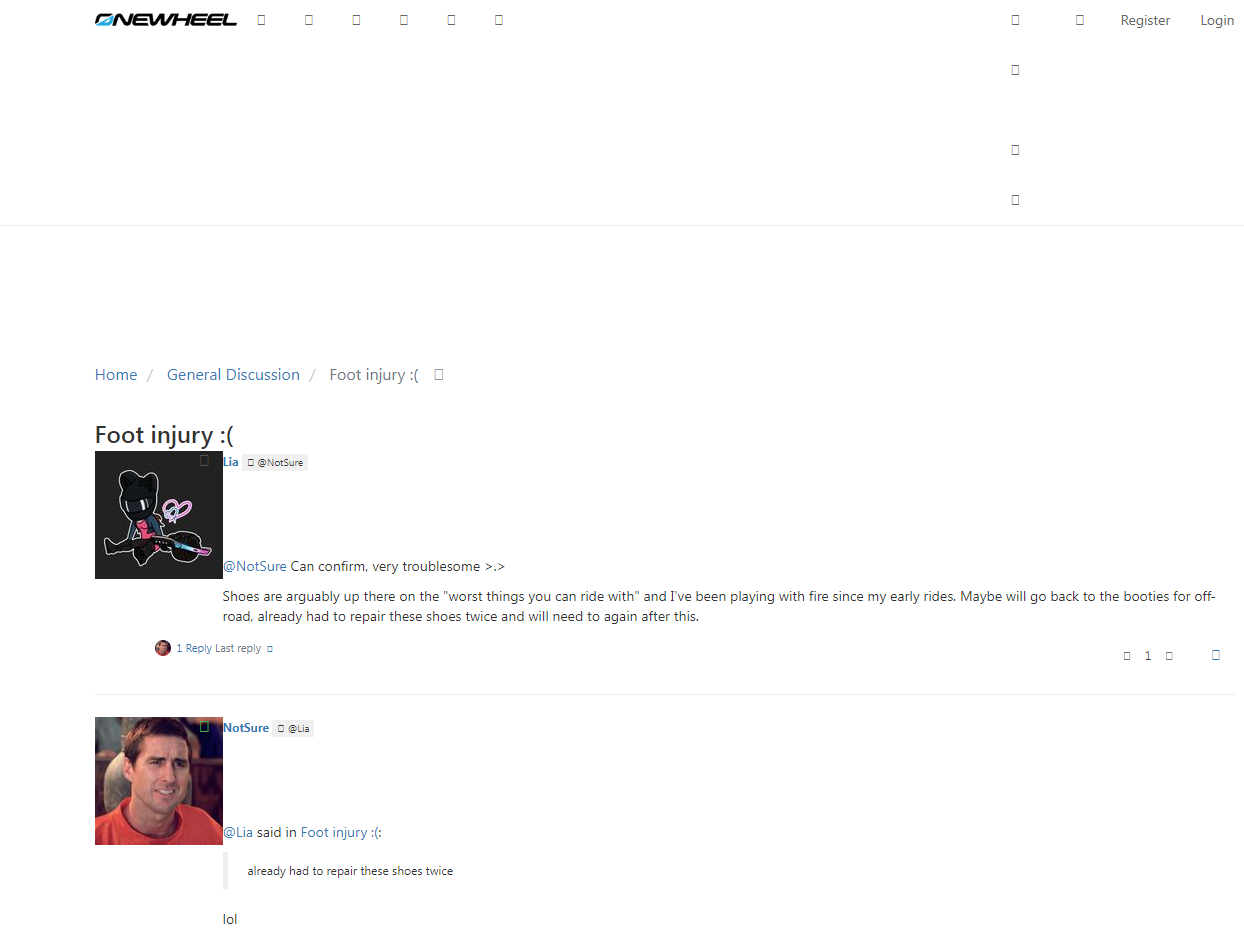
Icons and header is utterly borked compared to what you see on this working forum.I'm sure I'll find a streamlined way to do it eventually. Did want to make a python script but looking at the scope of it I realised the tool would have to be super complex to account for the variety of edge cases on the thousands of files. In the meantime I'll focus on the more popular and sort after topics.
-
@lia I wish you the best of luck! if there is somehow to help I am willing to put some time into it too :)
-
@cheppy44 Thanks :)
I think once I get a functional site up for it I might ask if anyone more competent can look over the pages (I'll make the html, css and scripts available) to see if there are better ways to achieve the desired function. -
@lia said in Organising the Archive:
Did want to make a python script but looking at the scope of it I realized the tool would have to be super complex to account for the variety of edge cases on the thousands of files. In the meantime I'll focus on the more popular and sort after topics.
This could either be super easy or super difficult to hem together the individual segments into a complete thread. It will depend upon how the server implements the tagging mechanism when generating each page.
that is where to start ur planning imo. how does the server store data and generate a page from that data.
then you just need to merge the properly cleansed data to a copy of the existing data set for testing. if it works, ur good.
Cleansing this much loosely structured data would certainly be a hellish chore manually, and even still as a scripted application.
Firstly, I'm a data analyst, not a web developer, so others may have better opinions. if i were to approach the problem, it would start with data cleansing.
Each data set would be programmatically cleansed of irrelevant data, leaving a simple html segment with the desired components.
the css for each html can be treated in two ways, either left alone and pray for no bugs, or tossed all together and redone. The html is what matters and can probably be stylized afterwards.
I would prefer the former solution cuz its easier, but i also find myself doing both in the end cuz u know... the universe.
u may not have to process tags any further since each page was likely generated procedurally, so they may be identically tagged.
my real hope would be for more or less plug and play css.
thats why i don't do front-end at all.
users r so nitpicky! just eat this wall of text u ape!
XR's got what plants crave!
